很多人给 Agent 选模型,第一反应是打开排行榜:哪个分数高,就把哪个塞进 Hermes。
这个思路看起来省事,实际很容易踩坑。因为 Agent 场景里,模型不是单纯回答问题,而是在连续判断:要不要调用工具、调用哪个工具、失败后要不要重试、上下文里哪些信息还重要、什么时候该停下来。
所以,真正的问题不是“哪个模型最聪明”,而是:哪个模型最适合你现在这类任务。
一组社区实测把这个差异暴露得很清楚。同样放进 Hermes,不同模型的性格差别非常明显:有的稳,有的快,有的会深想,有的工具调用更靠谱,也有的便宜但扛不住嵌套任务。
别找“最强模型”,先看任务类型
Agent 用模型,最怕只看单点能力。
写一段代码、解释一个概念、总结一篇文章,模型强一点弱一点,差距可能没有那么致命。但一旦进入 Agent 工作流,问题会变成链式的:
它要读文件、拆任务、调用工具、观察结果、修正计划、继续执行。前一步多绕一次,后面就可能多花几十秒;前一步漏掉一个上下文,后面就可能把整个任务带偏。
这也是为什么一些“看起来更强”的模型,在实际 Agent 场景里未必总是更舒服。
复杂推理能力很重要,但如果它经常过度思考,简单任务也会变慢。速度很重要,但如果它一遇到嵌套任务就掉链子,省下来的时间又会在返工里还回去。
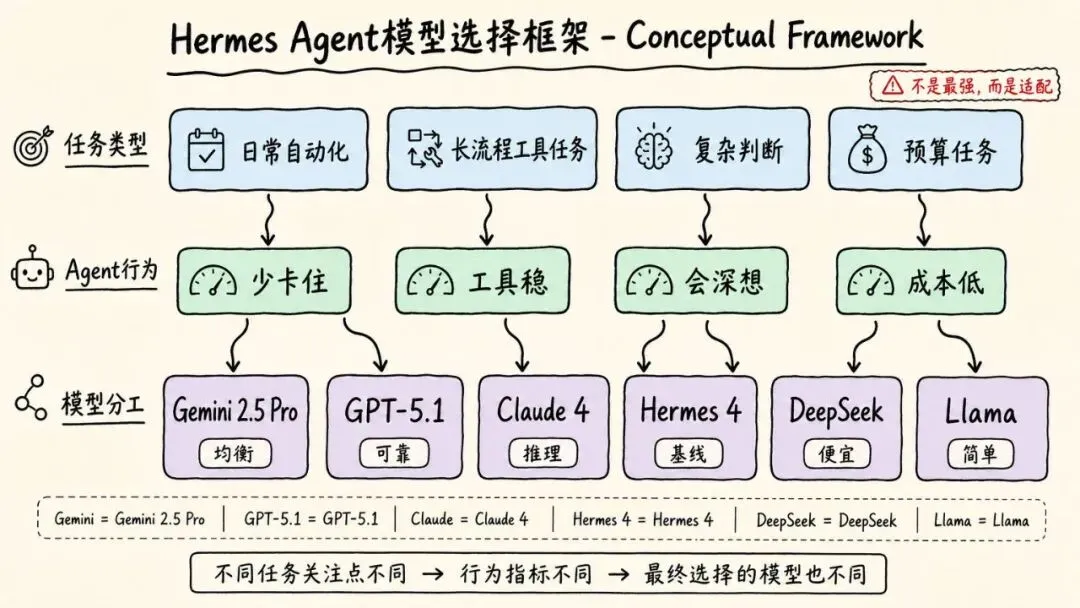
选 Hermes 模型,最好先把任务分成几类。
第一类:日常自动化,要的是少卡住
如果你每天主要让 Hermes 做整理资料、跑脚本、改小文件、查状态、生成简单内容,那么“均衡”比“天花板”更重要。
这类任务最怕两件事:一是模型在小问题上反复绕圈,二是工具调用失败后不知道收手。
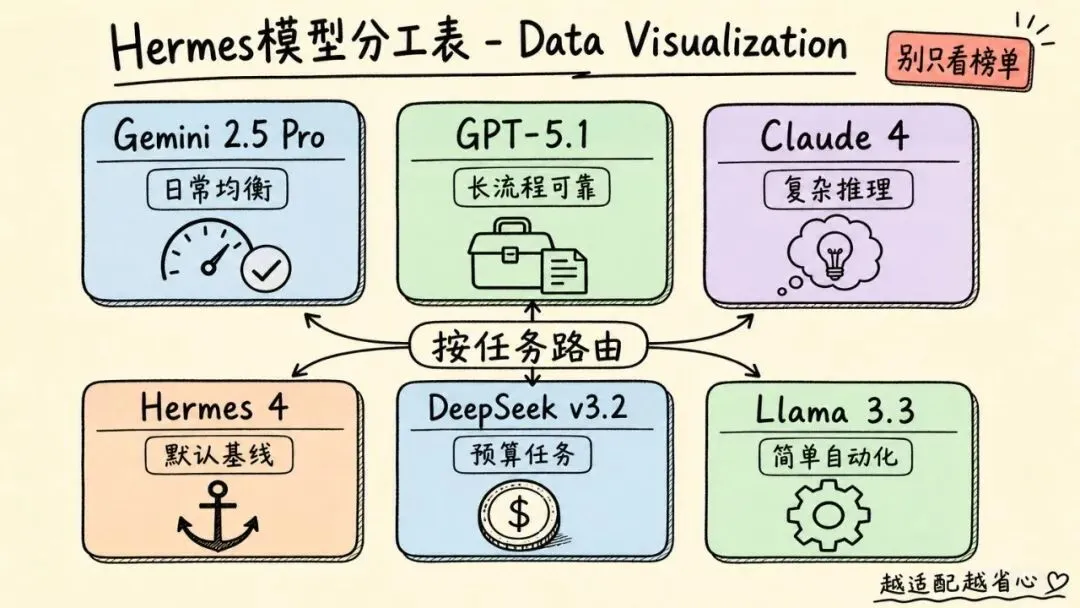
在这类场景里,Gemini 2.5 Pro 被很多人放在很靠前的位置,不是因为它每一道题都最强,而是因为它在多数日常任务里足够快、足够稳,而且不太容易陷入无意义的循环。
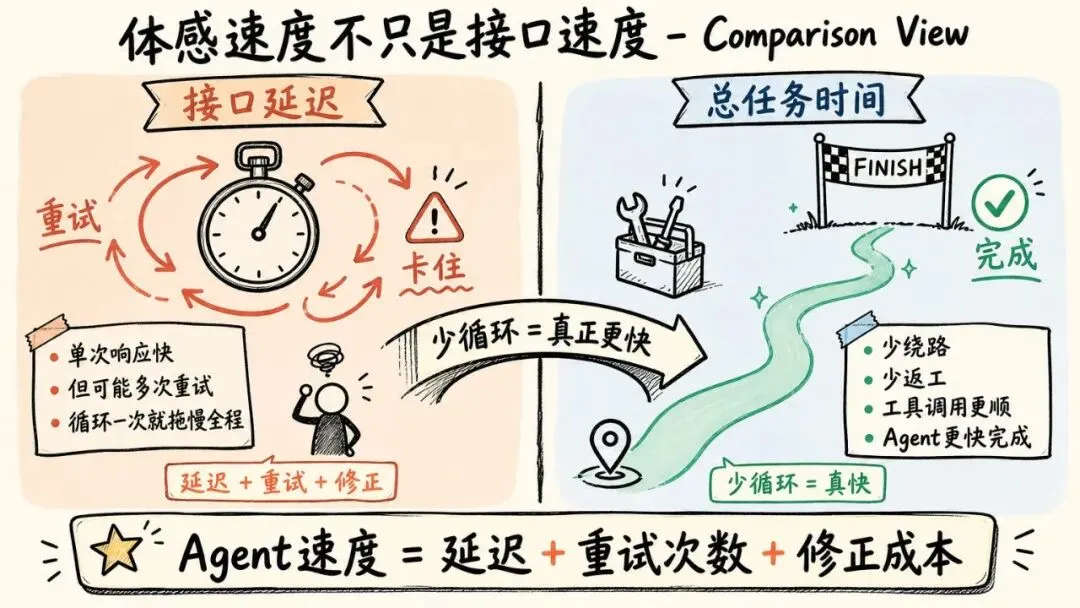
这里的“快”,不只是接口响应快。更关键的是少走弯路:少一次重试,少一次错误判断,整个 Agent 的体感就会轻很多。
但它也有一个现实问题:配额和可用性。任务一长、调用一多,很快就会碰到限制。把它当作日常主力可以,但不要把所有长任务都压在它身上。
第二类:长流程工具任务,要的是可靠
如果你的任务是多步骤的,比如让 Hermes 连续修改项目、生成文件、跑验证、根据报错继续修,那么模型能不能记住上下文、能不能稳定调用工具,就比单轮聪明更重要。
这类任务里,GPT-5.1 的优势会更明显:工具使用和上下文保持相对可靠,长会话里不容易突然忘记自己在做什么。
代价也很直接:成本会更高。尤其是你让它跑长任务、频繁读写文件、不断校验的时候,消耗会明显上去。
所以它更适合放在“关键任务”位置:不是每个小活都用它,而是在你不想中途接管、不想频繁擦屁股的时候用。
简单说:
日常任务追求顺手,关键流程追求可靠。
这两个目标不是一回事。
第三类:复杂判断,要允许它慢一点
Claude 4 Sonnet 的位置更像一个“深水区模型”。
当任务需要长链路推理、架构判断、复杂权衡,或者你需要它先想清楚再动手,它会更有价值。它的优势不是快,而是愿意把问题展开。
但这也是它的副作用:有时会想太多。
在简单任务里,过度谨慎会让 Agent 显得拖沓。你只是想改一个配置,它可能开始分析半个系统;你只是想跑一个命令,它可能先写一套策略。
所以 Claude 4 更适合被放在“难题模式”,而不是“默认模式”。
当任务真的复杂,它的慢是值得的;当任务很轻,它的慢就是成本。
第四类:基线和预算模型,别期待奇迹
Hermes 4 的价值在于稳定。它像一个默认基线:不惊艳,但可预期。你不知道该用什么时,它至少不会给你太多意外。
DeepSeek v3.2 更像预算选项。简单任务、成本敏感任务可以用,但当任务开始嵌套,表现就会变得吃力。
Llama 3.3 通过 OpenRouter 使用时,也更适合简单自动化:跑一些清晰、短链路、失败代价不高的动作。让它承担严肃多步骤任务,就容易暴露上限。
这里有个容易忽视的坑:第三方路由本身也会带来问题。
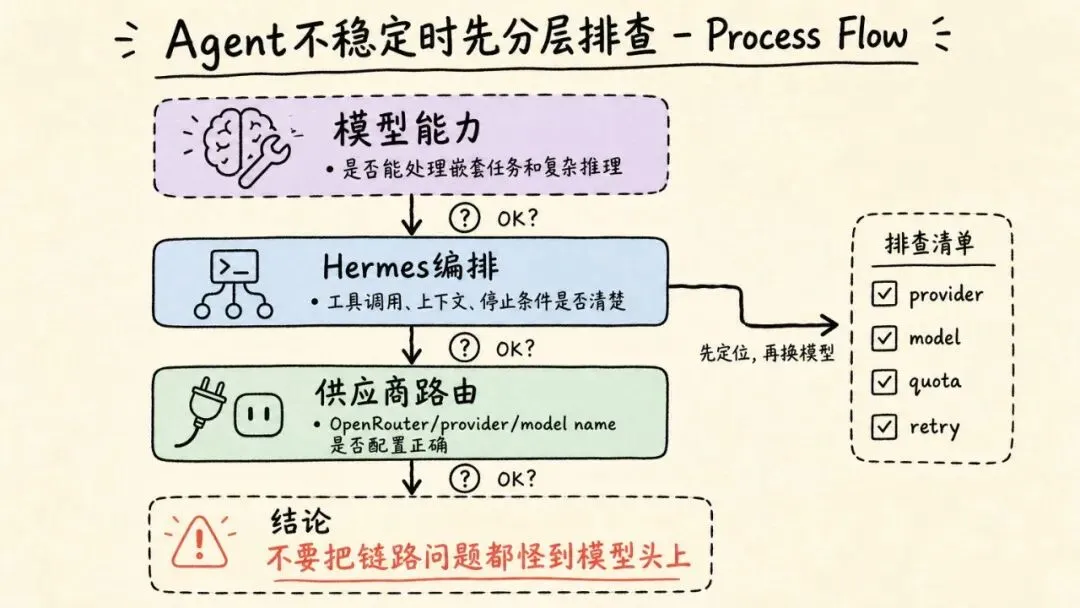
有些连接失败,看起来像模型不行,其实是 OpenRouter 的 provider routing、模型名称、供应商配置没配对。Agent 不稳定,有时不是模型问题,而是链路问题。
排查时要分清三层:
模型能力、Hermes 编排、供应商路由。
混在一起判断,很容易误杀一个模型,也很容易错怪工具。
真正好用的做法:给 Hermes 做模型分工
不要把模型选择变成信仰问题。
更实用的做法,是给 Hermes 准备一张小路由表:
- • 简单自动化:Llama 3.3 / OpenRouter
这张表不需要永远正确。它的价值是让你每次开任务前先问一句:
这次我到底要的是速度、稳定、便宜,还是深度?
Agent 时代,模型选择会越来越像“调度策略”,而不是“选一个冠军”。
一个团队可能不会只用一个模型。一个人做自动化,也不该只靠一个模型。
最后,别被榜单带着走
排行榜回答的是“模型综合能力如何”。
但 Hermes 这类 Agent 工具真正关心的是另一组问题:它会不会乱调用工具?会不会陷入循环?长任务会不会丢上下文?失败后会不会越修越偏?配额够不够?成本能不能接受?
这些问题,在榜单上通常不够显眼,却决定了每天使用时的体感。
所以,选模型时别只问“哪个最强”。
更应该问:
我的任务失败一次,代价有多高?
如果失败代价低,用便宜快的;如果失败代价高,用稳的;如果问题真的复杂,再把深推理模型请出来。
这才是 Hermes 选模型最值得记住的一句话:
模型不是越强越好,而是越适配越省心。