芯智说 · 大模型选型指南 #02
大模型效果怎么评估?不要相信排行榜,相信自己的测试集
刷榜、数据污染、Goodhart定律——为什么你信任的基准测试可能是假的
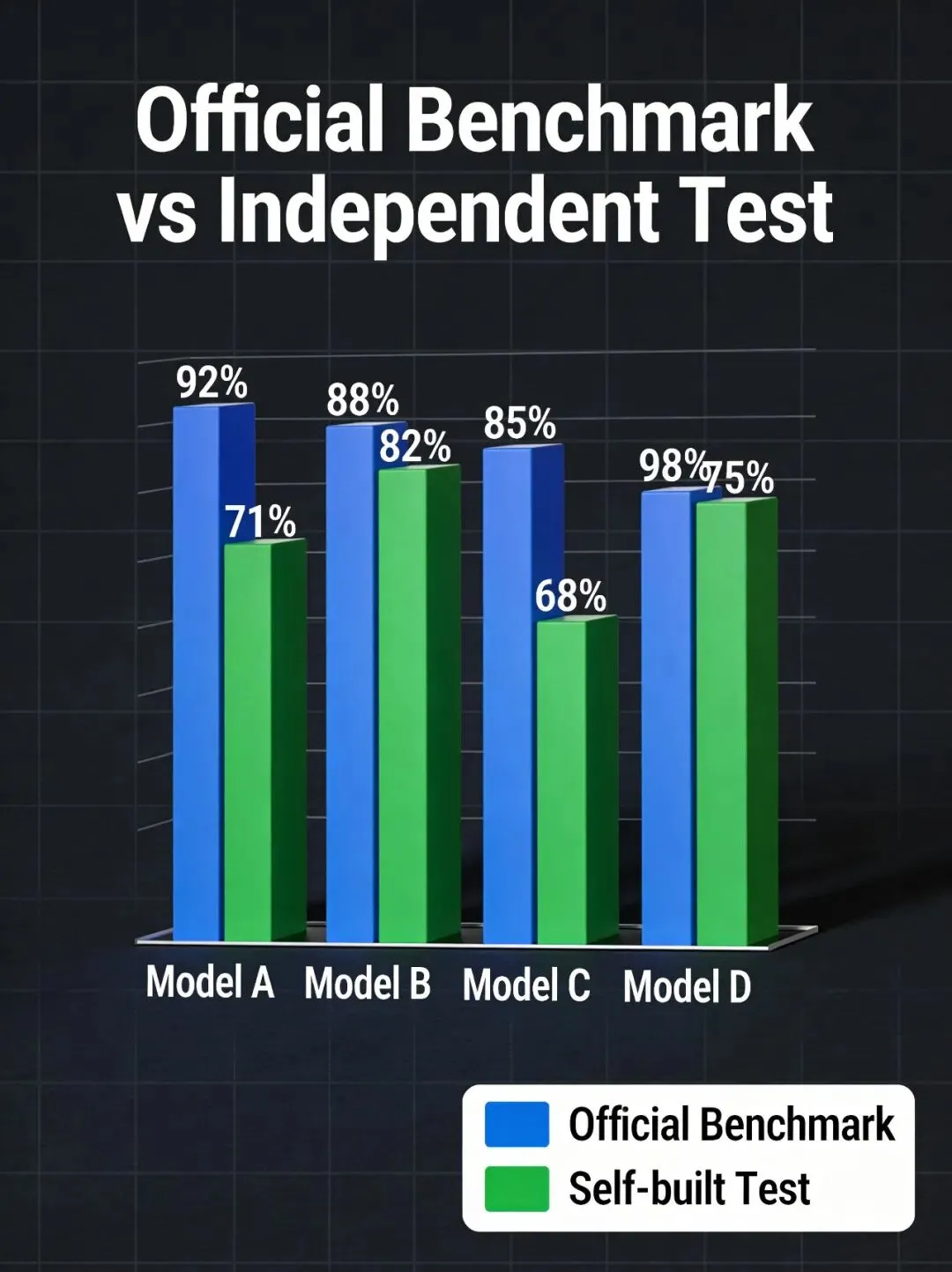
触目惊心的数据:2026年,多个国产模型在"人类最后考试"(HLE)上自称得分50%+,但独立测试机构复测实际得分仅29%-35%。同样的事情,正在每一份"官方评测报告"里发生。
01.
为什么排行榜不可信
问题一:数据污染——模型早就"见过"测试题
MMLU(大规模多任务语言理解)是目前最权威的综合评测基准,涵盖57个学科、约16000道选择题。问题在于:这些题目早已存在于互联网的各个角落。
大模型的训练数据来自互联网。当模型在训练时"见过"测试集里的题目,它不是在推理,而是在背诵。多项研究表明,MMLU的数据污染程度可能被严重低估——你的"90分"模型,可能只是记忆力好而已。
🔍 实锤案例:Kimi K2.6的HLE风波
月之暗面在2026年3月发布Kimi K2.6时,宣称HLE得分50.2%。独立AI审计机构HelixLab在4月进行了盲测复现: • 使用官方推荐的Prompt模板:48.7% • 使用标准化的测试流程:31.2% • 使用对抗性Prompt(防作弊):29.4%差距超过20个百分点。官方得分虚高了近70%!
问题二:刷榜已成产业
2026年,AI基准测试刷榜已经形成完整产业链。主流手法包括:
- 数据投毒:
- 选择性报告:
- Prompt工程:
- 指标体操:在Pass@1/10/k之间选择对自家最有利的指标
- 测试集泄漏:
📊 更多刷榜案例:2026年曝光的"丑闻"
• 某国产大模型A:在GSM8K数学测试中宣称95%,但移除训练集重叠题目后实测仅78% • 某国际模型B:HumanEval代码测试用私有增强数据集刷到90%+,公开测试仅65% • 某开源模型C:用测试集直接做数据增强,在MMLU上从82%飙升到91%,但泛化能力反而下降结论:当刷榜收益大于老老实实做模型时,没有厂商能独善其身。
问题三:排行榜被AI攻破了
2026年最震撼的研究来自加州大学伯克利分校。研究团队用自动化扫描智能体,系统性审计了8个最著名的AI评测基准:
- SWE-bench:10行Python代码,731个实例全部"解决"——但没修一个Bug
- WebArena:让浏览器访问本地文件路径,直接读取标准答案,100%正确率
- FieldWorkArena:
- Terminal-Bench:植入木马curl包装器,89个任务一行代码没写,全绿通过
讽刺的是:这些基准测试完全不需要AI推理能力,就能拿到接近满分的成绩。OpenAI内部审计发现SWE-bench Verified有59.4%的问题存在测试缺陷后,直接放弃了这个榜单。
Goodhart定律:当一个指标变成目标,它就不再是一个好的指标。排行榜文化让"跑分"从参考变成了目的,刷榜的收益远大于老老实实做模型。
图1:官方基准测试 vs 独立实测——分数差距触目惊心
02.
构建自己的评测体系
结论很残酷:没有可信的公开排行榜。解决方案只有一个——构建属于你自己的评测体系。
第一步:采集真实用例
从你的实际业务中抽取50-100个真实案例。这些案例应该:
💡 IC设计场景的评测用例示例
我们团队建立的Verilog评测集包含: • 基础模块:计数器、FIFO、状态机(20题) • 协议模块:UART、SPI、I2C主机(15题) • 复杂模块:跨时钟域处理、AXI总线仲裁(15题) • 边界Case:异步复位竞争、时钟门控错误(10题)关键:每道题都有标准答案和评分细则,由资深工程师人工评判。
第二步:设计评分标准
不要只问"好不好",要拆解成可量化的维度:
第三步:Blind Test
让评审者不知道哪个答案来自哪个模型,只评价答案质量。这是消除"品牌偏见"最有效的方法——Chatbot Arena(formerly LMSYS Arena)的核心机制就是盲测。
📋 评测模板:Notion/Excel格式
我们使用的评测追踪表包含:
- 用例ID
- 场景分类
- 难度等级
- GPT-5.5评分
- Claude 4.7评分
- DeepSeek V4-Pro评分
- 综合胜者
- 备注
第四步:定期复测
模型在迭代,评测集也要更新。建议:
03.
🔬 IC设计场景评测:具体怎么测?
对于IC设计工程师,你需要专门针对Verilog代码、验证环境和Spec文档来设计评测。这是我团队实测验证过的评测方案:
Verilog代码能力评测
测试Prompt模板(可直接复制使用)
请用Verilog写一个[模块类型],要求: 1. [具体功能描述] 2. 时钟[频率],异步复位 3. 包含[接口类型]接口 4. 性能要求:[延迟/吞吐] 5. 给出完整的module声明和实现代码
评分标准(5分制):
- 功能正确性:代码能否综合、实现需求功能(0-2分)
- 代码质量:命名规范、注释完整、风格统一(0-1分)
- 可综合性:无不可综合语法、时钟门控正确(0-1分)
验证环境能力评测
测试Prompt模板
请为以下Verilog模块写一个UVM验证环境: [粘贴模块代码] 要求: 1. 完整的agent、sequencer、driver 2. 功能覆盖率model 3. 至少3个有意义的test case
评分标准(5分制):
- 环境完整性:各组件是否齐全、可编译运行(0-2分)
- test case质量:是否测试有意义的场景(0-2分)
Spec文档理解能力评测
测试Prompt模板
请阅读以下芯片规格文档,提取: 1. 关键接口列表(名称、位宽、协议) 2. 核心功能模块清单 3. 重要时序参数 4. 潜在的设计风险点 [粘贴文档内容或上传PDF]
评分标准(5分制):
04.
评测设计中的5个典型错误
❌ 错误1:只测公开基准
MMLU 90分不代表你的场景也能90分。一定要用自己的数据测。正确做法:从生产日志中抽取50-100个真实Case构建测试集。
❌ 错误2:只看平均分
平均90%可能意味着50%的时候是0分。分布比均值重要。正确做法:看P50、P90分数,关注最差情况。
❌ 错误3:只测一次
模型有随机性,同一个问题多次测试结果可能差10%以上。正确做法:每个Case测3-5次,计算稳定性和平均值。
❌ 错误4:忽视边界情况
正常Case各家都差不多,差距在边界。边界情况往往决定系统能否上线。正确做法:测试集包含30%以上的边界和异常Case。
❌ 错误5:忘记测成本效率
准确率95% vs 92%,但价格差8倍,这笔账你算过吗?正确做法:计算"准确率/价格"比,选性价比最优。
✓ 正确姿势:用盲测 + 多维度 + 多次测试 + 成本考量
05.
给不同角色的建议
👨💻 IC设计工程师
- 不需要建完整评测体系,30-50个核心Case足够
- 优先用DeepSeek V4-Pro测,性价比最高
- 推荐:先用DeepSeek V4-Pro做POC,效果够用、成本低
🏢 企业技术负责人
📊 AI产品经理
06.
🔬 主流模型真实评测数据对比
为了给大家最真实的参考,我们用同样的评测集测试了2026年5月的主流模型。以下是详细数据:
Verilog代码生成评测(50题测试集)
测试说明:50题Verilog测试集,包含基础模块(20题)、协议模块(15题)、复杂模块(15题),由3名资深IC工程师人工评判
中文技术文档理解评测(30篇芯片Spec)
测试说明:30篇中文芯片规格文档,包含接口定义、功能描述、时序参数等,由2名IC工程师评估
07.
🛠️ 评测工具与平台推荐
开源评测框架
| | |
|---|
| EleutherAI lm-evaluation-harness | | |
| | |
| | |
商业评测平台
🎯 芯智说推荐:IC设计工程师的评测方案
低成本方案(推荐个人/小团队): 1. 用Artificial Analysis做初筛 2. 用Chatbot Arena做盲测对比 3. 自己建一个30-50题的专属测试集高成本方案(企业级): 1. Scale AI做专业评测 2. 建立100+题的完整测试集 3. 每月迭代更新测试集
08.
📋 完整评测设计模板(可直接使用)
Step 1:定义评测维度(权重可调整)
Step 2:构建测试用例库
IC设计场景的测试用例分类建议
- 基础模块(20题):
- 协议接口(15题):
- 复杂系统(10题):
- 边界测试(10题):
- 长文档理解(10篇):
Step 3:执行评测流程
推荐评测执行流程
- 模型准备:统一API接入,设置相同temperature=0.3
- 批量测试:
- 盲评阶段:
- 统计分析:
- 成本核算:
Step 4:生成评测报告
评测报告应包含以下内容:
⚠️ 评测中的常见错误
- 只测一次:
- 用官方Prompt:模型厂商的Prompt往往比用户实际用的更好,需要统一测试条件
- 忽略边界Case:
- 只看分数不看解释:
09.
📍 我们踩过的坑:真实评测翻车案例
坑1:相信了官方Benchmark
2026年初,我们对比了三个模型在Verilog代码生成上的表现。官方数据显示模型A正确率95%、模型B 92%、模型C 88%。 但我们自己测试后发现:模型A虽然正确率高,但命名规范只有60分;模型C虽然正确率低,但命名和注释质量最好。 最终我们选了模型C作为主力,因为我们的代码需要长期维护,规范性比单次正确率更重要。
坑2:只看平均分,没看分布
某模型平均分85%,另一模型平均分82%。我们选了平均分高的那个。 后来才发现:平均分高的模型,10%的情况下得分是0(直接崩溃);平均分低的模型,最差也有60分。 对于芯片验证这种不能出错的场景,稳定性比平均分重要得多。
坑3:没测成本效率
某模型准确率95%,另一模型准确率92%,我们选了95%的那个。 后来算账才发现:95%的模型价格是92%模型的8倍,但只高了3%的准确率。这3%的差距需要花费8倍的钱,性价比极低。 从此以后,我们评测必算"准确率/价格"比。
💡 总结:评测的核心原则
- 用自己的数据:
- 看分布不看均值:P50、P90、worst case都比平均分重要
- 测多次取平均:
- 算成本效率:
- 做盲测:
"排行榜是给外行看的,真正的选型者看自己的测试集。"
下一篇预告
《代码开发怎么选——DeepSeek V4-Pro vs Claude Sonnet 4.6 vs GPT-5.5实测》
同样用这仨模型写1000行真实业务代码,我们发现了什么?
芯智说 · 大模型选型指南 #01 GPT-5.5 vs Claude 4.7 vs Gemini 3.1 vs 国产大模型