大模型评测榜单解读及模型选型指南
- 更新时间 2026-05-19 09:22:30
本文是「大模型入门」系列的第四篇。 前三篇我们解决的是"硬件层面"的问题——这台机器跑不跑得动、跑得快不快、用什么格式跑。本篇往上走一层,解决"模型层面"的问题:在跑得动的前提下,到底该选哪个模型。
如果你是第一次看到这个系列,建议按顺序读完前三篇:
1. 大模型推理精度与显存估算指南——搞清楚一个模型到底要吃多少显存,你的卡能不能装下。 2. 大模型推理速度、显存带宽与显卡选型指南——装得下之后,跑得够不够快,该买什么显卡。 3. 大模型不同模型格式入门指南——同一个模型有 GGUF、AWQ、GPTQ 等多种格式,该用哪一种。
读完前三篇,你已经能回答"我的硬件能跑什么"。但还剩一个更上游的问题:能跑的模型那么多,哪个才是真正适合我的? 这正是本篇要解决的。每当新模型发布,厂商的发布会和技术报告里总会甩出一大堆跑分图表——"MMLU 91.2"、"SWE-bench 87.6%"、"Arena 1504"——这些数字看着专业,却很难判断真假优劣。本篇就教你看懂这些榜单,并把它们变成可靠的选型依据。
先看一个例子:DeepSeek V4 的发布榜单
2026 年 4 月 24 日,DeepSeek 发布了开源旗舰 V4(分 V4-Pro 与 V4-Flash 两个版本,均原生支持 100 万 token 上下文)。它的技术报告里给出了一张典型的"发布跑分表",下面是 V4-Pro 几个有代表性的官方分数,以及它和同代旗舰的对位关系:
表中数字与对照对象均来自 DeepSeek V4 发布时(2026 年 4 月)的技术报告,所以"同代对照"列里出现的是当时的 Claude Opus 4.6——之后 Anthropic、OpenAI 又发布了 Opus 4.7、GPT-5.5 等更新版本,本文后文引用的就是这些更新数字。这本身也说明了一件事:任何发布跑分表,对照的都是"发布那一刻"的竞品,几周后就可能过时。
单看这张表,很容易得出"V4-Pro 已是世界顶级"的结论——毕竟 LiveCodeBench 全场第一、SWE-bench 紧咬 Claude。但如果你读完本篇文章,就会用完全不同的眼光看它。
关于文中的具体分数:本文出现的所有具体数字(如 SWE-bench 88.7%、HLE 44.7%、LMArena 1504)都是某一时点的快照,且其中相当一部分是厂商自报、或由第三方站点汇总厂商自报分而来,各来源更新节奏不一。这些数字仅用于让你感受"模型大致处在哪个梯队",不要当成精确、权威、可长期引用的定论。大模型每 1–3 个月就有重大更新,看到本文时请务必重新核对。
写在前面:为什么需要这份文档
面对那一大堆跑分数字,初学者通常会卡在四个问题上:
• 这些榜单分别在测什么? • 数字高就一定好用吗? • 我该信哪个榜单? • 怎么用榜单帮我选一个适合自己的模型?
这份文档就是来回答这四个问题的。读完后,你应该能看懂任何一场大模型发布会的"跑分 PPT",并且知道哪些数字值得信、哪些只是营销话术。
我们先建立几个基础概念,再逐一拆解主流榜单,最后给出一套实用的选型方法。
第一部分:三个必须先搞懂的基础概念
1. "基准测试"(Benchmark)是什么
可以把基准测试理解为给大模型出的一套标准化考卷。比如出 1 万道选择题,让所有模型都做一遍,谁答对得多谁分高。这套考卷一旦固定下来,就能横向对比不同模型、也能对比同一个模型的不同版本。
基准测试的最大优点是可复现、可量化——同样一套题,今天测和明天测结果应该一致。最大缺点后面会讲(数据污染)。
2. "榜单"(Leaderboard)与"基准"的区别
很多人把这两个词混着用,但严格说有区别:
• 基准(Benchmark):是那套"考卷"本身,比如 MMLU、SWE-bench。 • 榜单(Leaderboard):是把很多模型在一个或多个基准上的成绩汇总排名的网站或榜单,比如 LMArena、Artificial Analysis。
一个榜单背后可能用了好几个基准。理解这个区别,你就不会再把"MMLU"和"LMArena"当成同一类东西了。
3. 评测分成几大流派:客观题、人类投票,以及新兴的智能体评测
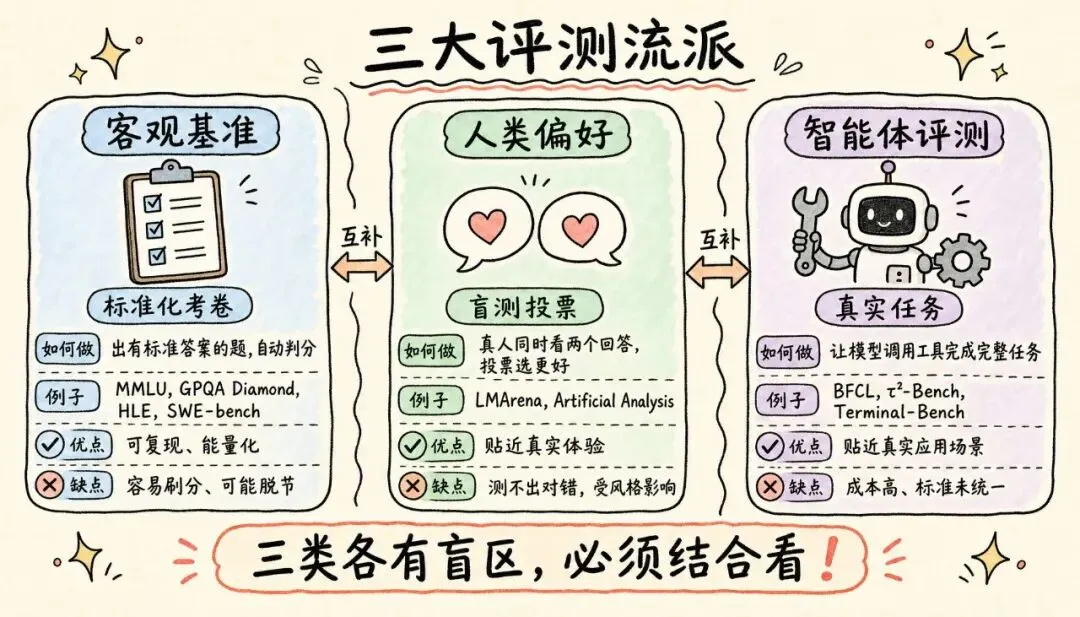 目前的评测方式可以归为两大主流流派,外加一类正在快速兴起的新方式:
目前的评测方式可以归为两大主流流派,外加一类正在快速兴起的新方式:
| 客观基准 | |||
| 人类偏好评测 | |||
| 智能体 / 裁判模型评测 |
前两类是主线,初学者先牢牢抓住它们即可。第三类(对应后面的"类别四")之所以单列,是因为它既不是传统的有标准答案的选择题,也不是单纯的真人盲测——它测的是"模型能不能像员工一样把一件事办完"。随着智能体应用普及,这一类会越来越重要。
每一类都各有盲区,必须结合起来看,任何单一榜单都不能代表一个模型的全部。
第二部分:主流榜单逐一拆解
下面把目前业界公认的榜单分成几大类介绍。每类我会说明:它测什么能力、怎么测、代表性榜单、以及看它时要注意什么。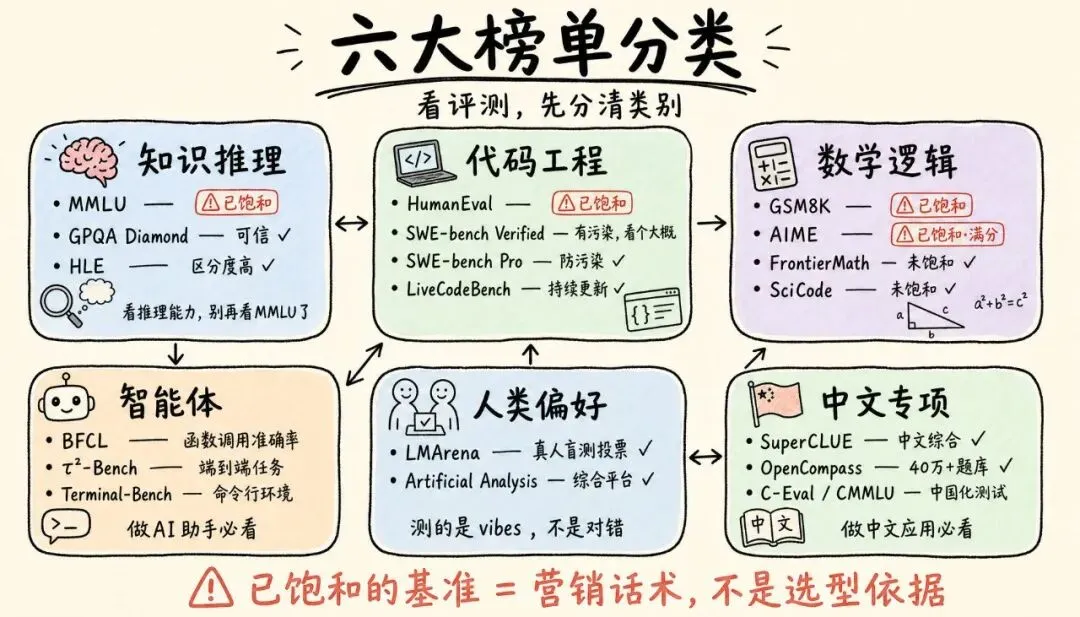
类别一:综合知识与推理(模型的"基础学历")
这类基准测的是模型懂多少知识、能不能进行多步推理。它们是最经典、被引用最多的一类。
MMLU(大规模多任务语言理解)
• 谁出的:2020 年由伯克利、CMU、斯坦福联合发布。 • 测什么:覆盖 57 个学科(医学、法律、历史、物理等)的 4 选 1 选择题,衡量模型的知识广度。 • 现状(重点):MMLU 在 2021 年是开创性的难题,但到 2026 年已经"饱和"了——所有前沿模型在它上面的得分都超过 90%,挤在一起,根本分不出高下。换句话说,今天一个模型 MMLU 考 91 分还是 92 分,几乎没有参考价值。 如果一场发布会还在重点炫耀 MMLU 分数,说明它的话术有点过时了。 • 升级版:为了解决饱和问题,业界推出了 MMLU-Pro(选项从 4 个增加到 10 个,约 1.2 万道研究生难度题)、MMLU-Redux(优化了原题偏差)、MMLU-ProX(多语言版本,覆盖约 29 种语言)。这些升级版目前还有区分度。
GPQA Diamond(研究生级别科学问答)
• 测什么:198 道需要真正多步科学推理的难题,设计上力求"防搜索"——用搜索引擎也查不到答案。 • 难度参照:这道题集有意思的地方在于它给了人类参照——拥有博士学位的专家做这套题正确率约 65%,而能上网查资料的非专业人士只能到约 34%。 • 现状:它不再是绝对最难的测试,但仍是最受尊重的推理基准之一,因为它的题目确实需要真本事。前沿模型目前在它上面大约能到 94% 左右。 • 看它时要注意:GPQA Diamond 只有 198 道题。题量这么小,意味着多答对或答错 2 道题,分数就会波动约 1 个百分点。所以当你看到"A 模型 94.1%、B 模型 93.6%"时,这 0.5 个百分点很可能只是测量噪声,不代表 A 真的比 B 强。引用小样本基准的分数时,要把它当成"一个带误差的估计",而不是精确数值。
Humanity's Last Exam(人类最后的考试,简称 HLE)
• 谁出的:由 Center for AI Safety 和 Scale AI 牵头,全球近 1000 名学科专家(分布在 50 个国家、500 多所机构)共同出题,2026 年初正式发表在《自然》(Nature)杂志上。 • 测什么:2500 道横跨 100 多个学科的专家级超难题,从翻译古代铭文到识别鸟类微小解剖结构都有。每道题都有唯一、可验证的答案。 • 现状(重点):这是目前最难的学术基准之一。即使是最强的模型,得分也很低——截至 2026 年 5 月,排在最前面的模型(如 Gemini 3.1 Pro Preview thinking)也只有约 47%,大多数前沿模型在 30% 左右。 • 关于"防污染"的准确说法:HLE 的设计目标是让题目无法靠搜索得到。但"防污染"是设计意图,不是已经实现的既成事实——HLE 有一个公开数据集,这部分题一旦公开就可能被拿去训练模型。出题方自己也承认:HLE 分数上升,既可能是模型能力真的提高了,也可能只是模型针对公开题集做了额外训练(相当于背了往年真题)。真正起"防污染"作用的,是 HLE 保留的一份不公开的测试集(held-out set)。所以看 HLE 分数时,要意识到公开部分仍有污染风险。 • 看它时要注意:正因为难,HLE 的区分度很好,是当前判断"顶尖推理能力"的关键指标。但出题方强调,它测的是"专家级学术答题能力",不等于"智能"或"AGI"——即使考到 100 分也不代表模型有自主研究、创造能力。另外学界发现它部分理科题的答案本身可能有错(估计错误率 18%–29%),所以也不能当成绝对真理。
看一个模型的"基础学历",别再只看 MMLU,要看 GPQA Diamond 和 HLE 这类还没饱和的难基准。
类别二:代码与软件工程(模型的"程序员能力")
这是 2026 年最受关注的能力维度,因为大量实际部署都是让模型自动写代码、修 bug。
HumanEval
• 测什么:OpenAI 在 2021 年随 Codex 论文发布的代码基准,仅 164 道 Python 题,且只测"函数级补全"(给一个函数签名和说明,让模型补全函数体)。 • 先解释一下"pass@k":这是代码基准常用的评分口径。它的意思是——让模型对同一道题生成 k 个答案,只要其中至少有一个能通过测试用例,这道题就算做对。所以 pass@1(只给一次机会)和 pass@10(给十次机会取最好)是完全不同的口径,数字差别很大。看任何代码分数时,第一件事是确认"这是 pass@几"——厂商报分时常挑对自己有利的口径。 • 现状:HumanEval 早该退役,原因不只是"饱和"(前沿模型 pass@1 普遍超过 93%),更是它有结构性缺陷:题量太少(164 道)、范围太窄(只有 Python、只有函数补全)、且题目早已公开被污染。这四个问题叠加,使它无法反映真实的工程能力。已被下面的 SWE-bench 取代为主要的代码能力信号。
SWE-bench Verified(软件工程基准 · 验证版)
• 测什么:这是目前业界说"SWE-bench 分数"时默认指的版本。它给模型真实的 GitHub issue(来自 Django、Flask 等知名开源项目),让模型生成补丁去真正修复这个 bug,由人工验证过的 500 道题组成。这比做选择题真实得多。 • 现状(2026 年 5 月的快照):头部成绩已经很高,前几名挤在 85%–89% 区间(如 GPT-5.5、Claude Opus 4.7、GPT-5.3 Codex);再往下 DeepSeek V4-Pro 等开源旗舰挤在 80% 上下。具体数字会很快变化,记住"头部已接近 90%、彼此差距很小"这个形势即可。 • 看它时要注意(非常重要):SWE-bench Verified 有几个叠加的问题。第一是数据污染——这些开源项目的代码和 issue 很可能早就进了模型的训练数据,模型可能"见过答案";OpenAI 的审计确实发现,被测的前沿模型能逐字复现某些题目的标准答案。第二是基准自身的质量缺陷——OpenAI 审计还发现,Verified 中最难的那批未解出题目里,约 59% 的测试用例本身有缺陷(会把正确答案判为错误)。一个常被引用的对比是:同一个模型,在 Verified 上能考 80% 上下,换到更难的 Pro 版本上会明显下滑(早期数据里有模型从 80% 掉到 46% 左右)。但要注意,这种落差不能单纯归因于"污染":它是"污染 + Pro 任务更难更长 + Pro 覆盖多种语言而 Verified 只有 Python + 基准质量缺陷"几个因素的混合结果。结论是:SWE-bench Verified 的分数只能当作"大致方向",不能当作精确测量。 一个考 80% 的模型几乎肯定比考 40% 的强,但 87% 和 88% 之间的差距没有数字看起来那么有意义。
SWE-bench Pro
• 测什么:由 Scale AI 构建的更新、更难版本,约 1865 道多语言任务(覆盖 Python、Go、TypeScript、JavaScript 等),并保留一份不公开的测试集,设计目标是"防污染"。 • 现状:因为更难、更防污染,分数明显低于 Verified;但随着模型迭代,头部分数也在快速上升(头部模型已从早期的 40% 出头升到 60% 以上)——所以不要记某个具体数字,记住"它比 Verified 低一截、且会随模型更新而变"即可。 • OpenAI 的官方立场,以及一个值得玩味的矛盾:2026 年 2 月,OpenAI 官方发文宣布不再报告 SWE-bench Verified,理由正是上面说的污染与质量缺陷,并建议全行业改用 SWE-bench Pro。但有意思的是——OpenAI 自己在随后发布新模型时,营销材料里仍然给出了 Verified 分数。这恰好印证了后面"陷阱 3"要讲的:厂商嘴上说的评测标准,和它发布会上实际拿来宣传的数字,可以是两回事。 • 看它时要注意:如果你想知道模型相对更真实的代码能力,SWE-bench Pro 比 Verified 更可信;但要知道,后来也有独立审计指出 Pro 自身同样存在题目质量问题(如测试过于宽松)。没有完美的基准——这是看任何榜单都要记住的要点。
其他代码相关基准:LiveCodeBench(实时竞赛编程题,持续更新所以不易污染)、Terminal-Bench(命令行 / 终端环境任务)、Aider Polyglot(多语言代码编辑)。
看代码能力,SWE-bench Verified 看个大概排名就行,真要较真请看 SWE-bench Pro 和 LiveCodeBench 这类防污染基准。
类别三:数学与逻辑推理
GSM8K
• 测什么:2021 年 OpenAI 发布的 8500 道小学水平数学应用题,测多步推理链。曾是必测项,现在对前沿模型来说已经太简单,基本饱和。
AIME(美国数学邀请赛)
• 测什么:用真实的美国高中数学竞赛题(每年一套,通常按年份命名,如 AIME 2024、AIME 2025),测高难度数学推理。 • 现状:AIME 在 2026 年中已基本饱和,不再是有区分度的基准。以 AIME 2025 为例,在 Artificial Analysis 等独立榜单上,GPT-5.2、GPT-5 Codex、Gemini 3 Flash 等多个前沿模型都已达到满分(100%)。 • 两个必须知道的限定:第一,部分"满分"是在允许模型调用工具(如 Python 计算器) 的设定下取得的;带工具和不带工具是完全不同的两种评测,看分数时要分清。第二,AIME 题目和答案是公开的,存在污染——一个典型信号是:模型在较老的 2024 年题目上往往比 2025 年新题表现更好,这说明它可能"背过"老题。正因如此,影响力很大的第三方平台 Artificial Analysis 在其智能指数 v4.0 中已经把 AIME 2025 移除。 • 结论:AIME 已经和 MMLU、GSM8K 一样,从"区分性基准"退化为"营销基准"。发布会若重点炫耀 AIME 满分,参考价值有限。
FrontierMath / SciCode
• 测什么:应用层面的数学和科学计算问题,难度高到目前仍能挑战最强模型。属于目前还没饱和、仍有区分度的数学/科学基准——这才是真正能区分数学高手的基准。
GSM8K、AIME 这类传统数学竞赛题都已经饱和(AIME 2025 已被多个模型刷满,且存在污染);真正能区分高手的是 FrontierMath、SciCode 这类还没被攻克的基准。
类别四:智能体与工具调用(模型的"实际办事能力")
随着 2026 年"AI 智能体(Agent)"成为主流应用形态,这一类的重要性急剧上升。它测的不是"答对题",而是"模型能不能像一个员工一样,调用工具、分步骤完成一个真实任务"。
• BFCL(伯克利函数调用排行榜):衡量工具使用、函数调用的准确率。在智能体部署成为主流的 2026 年,这个指标越来越关键。 • τ²-Bench / Terminal-Bench Hard / GDPval:模拟真实工作场景(如电信客服、终端运维、覆盖经济价值的真实工作任务),测模型端到端完成复杂任务的能力。 • SuperCLUE-Agent:中文原生的智能体任务评估基准。
如果你的用途是搭建自动化工作流、做 AI 助手,这一类基准比知识类基准更值得你关注。
类别五:人类偏好盲测(模型的"真实体验感")
前面四类都是"客观题"。这一类是另一个流派——让真人来投票。
LMArena(原 Chatbot Arena / LMSYS)
• 怎么测:这是最有名的人类偏好榜单。它的机制很巧妙:用户提一个问题,系统匿名地同时返回两个模型的回答(用户不知道哪个是哪个),用户投票选哪个更好。海量投票之后,据此给模型排名。 • 它用的评分方法:很多文章说 LMArena 用"Elo 积分系统",这个说法已经过时。LMArena 在 2023 年底就从在线 Elo 切换到了 Bradley-Terry(BT)模型。简单理解:BT 是 Elo 背后那套数学模型的更严谨版本,它假设模型实力不随时间变化、并对全部历史对局做集中式统一计算,因此比在线 Elo 更稳定、误差范围更精确。榜单上的分数仍沿用类似 Elo 的数值量纲(所以你还会看到"Arena Score / Elo"的叫法),但底层算法是 BT。 • 它代表什么能力:它反映的是真人在实际对话中更喜欢谁——回答是否自然、是否听懂了复杂指令、创意写作是否出色。它不是厂商自己报的分,所以可信度较高。 • 现状(截至 2026 年初/中):头部被 Claude Opus 4.6/4.7、Gemini 3 系列、GPT-5 系列、Grok 4 等占据,前列分数大致在 1450–1560 区间。值得一提的是,中国模型也在密集登榜——字节 Seed 2.0 一度进入综合榜全球前十,智谱 GLM、阿里 Qwen、月之暗面 Kimi 等也陆续进入榜单前列。
- 看它时要注意(重要,且容易被忽略):
• 一定要看分数后面的"±值"(置信区间)。LMArena 每个分数都带误差范围,比如 1504±5,意思是"真实分数有 95% 的可能落在 1499–1509 之间"。头部几名模型的误差范围经常互相重叠——这意味着排第 1 和排第 3 的模型,在统计上其实是打平的,谁前谁后部分只是噪声。正确的读法是:先看置信区间,再看名次。 • 投票数不足的模型会被标"Preliminary(初步)",它们的误差范围更宽(±10–15,而成熟模型只有 ±4–7),排名更不可靠。 • LMArena 测的是"体验"和"偏好",不直接测对错和推理深度。一个模型可能因为回答风格讨喜而排名靠前,但这不代表它在硬核逻辑题上更强。所以业界有句话:LMArena 测的是"vibes(感觉)",HLE 测的是"hard reasoning(硬推理)",两者经常对不上。两个都要看。
Artificial Analysis(综合分析平台)
• 怎么测:它不是单纯的人类投票,而是一个多维度综合平台,同时评估模型的"智能、速度、成本、延迟"四个维度,每隔几十小时更新一次。 • 它的"智能指数(Intelligence Index)":这是一个复合指标,把 10 个高难度评测(GDPval、τ²-Bench、Terminal-Bench Hard、SciCode、HLE、GPQA Diamond、CritPt 等)按权重加总成一个分数。2026 年 1 月它升级到 v4.0 时,特意移除了 MMLU-Pro、AIME 2025、LiveCodeBench——因为这三个"被厂商营销引用最多"的基准已经饱和了。这个动作本身就说明了"饱和基准不再有意义"。 • 看它时要注意:这种复合分数的好处是不容易被单一基准带偏;但缺点是一个总分(比如"57 分")会掩盖模型在不同子项上的巨大差异——三个总分都是 57 的模型,可能一个强在智能体、一个强在科学推理。所以别只看总分,要点进去看分项。另外,Artificial Analysis 是一家商业评测公司的产品,把它当作"一个有用的参考",而不是"官方权威认证"。
LMArena 给你"真人喜不喜欢"的信号,Artificial Analysis 给你"覆盖最广、还带价格速度"的信号。但人类投票测不出对错,复合总分会掩盖分项差异。
类别六:中文专项榜单(中文场景必看)
如果你主要用中文,前面那些以英文为主的榜单不够,需要专门看中文榜单。
• SuperCLUE:针对中文通用大模型的综合性测评基准,每月更新。覆盖语言理解与生成、专业技能与知识、智能体、安全性四大能力象限。它还包含一个匿名对战的"琅琊榜"(类似中文版 LMArena)。 • C-Eval / CMMLU:中文版的多学科知识评估基准。CMMLU 尤其强调"中国特定知识"——比如中国驾驶规则这种在别的语言里不通用的题目,是非常"中国化"的测试。 • OpenCompass(司南):上海人工智能实验室推出的开源评测体系,覆盖学科、语言、知识、理解、推理五大维度,提供 70 多个数据集约 40 万道题。它旗下的 CompassArena 是基于中文用户真实投票的对战榜单。 • FlagEval(天秤):智源研究院推出的评测平台,采用"能力—任务—指标"三维框架。
做中文应用,务必把 SuperCLUE、OpenCompass 这类中文榜单和国际榜单一起看。中国开源模型(如阿里 Qwen、智谱 GLM、DeepSeek、月之暗面 Kimi、MiniMax 等系列,各自快速迭代,2026 年中的代表版本如 DeepSeek V4、GLM-5.1、Qwen3.6、Kimi K2.6)在中文场景和性价比上往往很有竞争力——尤其是 API 价格,常比同级国外闭源模型低一个数量级。
第三部分:榜单的"陷阱"——为什么不能只看分数
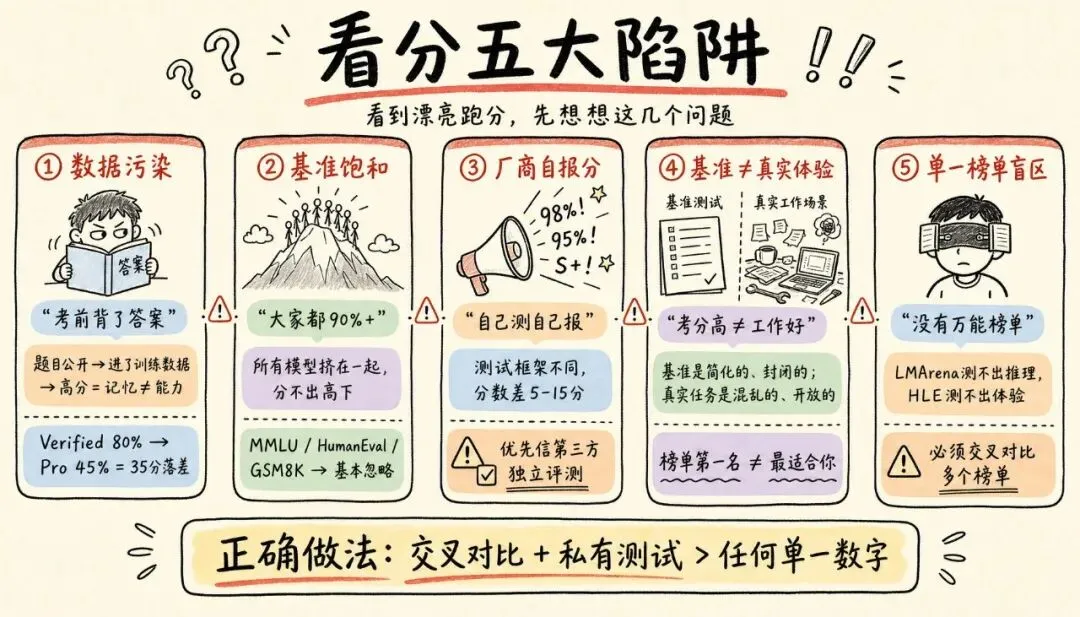 这部分是初学者最容易忽视、却最重要的内容。看到漂亮的跑分时,请先想想下面几个问题。
这部分是初学者最容易忽视、却最重要的内容。看到漂亮的跑分时,请先想想下面几个问题。
陷阱 1:数据污染(刷分)
最严重的问题。如果一个基准的题目和答案在互联网上是公开的,那它们很可能进了模型的训练数据——模型相当于"考前背了答案"。这时高分反映的是"记忆",不是"能力"。
怎么识别:看一个模型在"防污染"基准上的表现是否和"易污染"基准一致。如前所述,某模型在 SWE-bench Verified 上 80.9%,在防污染的 SWE-bench Pro 上只剩 45.9%——这 35 分的落差就是污染的代价。
陷阱 2:基准饱和
当所有顶尖模型在一个基准上都考 90% 以上,这个基准就"饱和"了,失去了区分能力。MMLU、HumanEval、GSM8K 都已饱和。一场发布会如果重点炫耀这些饱和基准的分数,你应当警惕。
陷阱 3:厂商自报分(self-reported)
许多技术报告里的分数是厂商自己测、自己报的。不同厂商用的测试脚手架(scaffolding)、提示词、重试策略都不同,结果未必可比。同一个基准,换个测试框架,分数可能差 5–15 分。
怎么应对:优先信任第三方独立评测(如 Artificial Analysis、LMArena、Epoch AI、Scale AI 的 SEAL 榜单),对厂商自报分打个折扣。
陷阱 4:基准 ≠ 真实体验
斯坦福 2026 年 AI Index 报告里有一句话很到位(大意):知道一个法律推理基准有 75% 准确率,并不能告诉你它在真实律所工作中表现如何。基准是简化的、封闭的;真实任务是混乱的、开放的。榜单第一名不等于最适合你。
陷阱 5:单一榜单的视野盲区
没有任何一个榜单覆盖所有能力。LMArena 给你人类偏好,但测不出推理深度;HLE 给你硬推理,但测不出对话体验;Artificial Analysis 覆盖最广,但它只是一家商业公司的产品。正确做法永远是交叉对比多个榜单。
第四部分:如何用榜单确认一个模型的综合能力
把前面的内容整合成一套可操作的方法。判断一个模型的综合实力,建议按这四步走。
第一步:先看一个第三方复合榜单,建立总体印象。打开 Artificial Analysis 的智能指数,或 LMArena 的综合榜,看这个模型大致处在什么梯队(头部 / 中部 / 尾部)。这一步只是定位,不下结论。
第二步:拆开看分项,而不是只看总分。点进复合榜单的分项,或者去查这个模型在各个未饱和基准上的单项成绩:
• 知识与推理 → 看 GPQA Diamond、HLE • 代码 → 看 SWE-bench Pro、LiveCodeBench(SWE-bench Verified 只作参考) • 数学 → 看 FrontierMath、SciCode(AIME、GSM8K 已饱和,参考价值低) • 智能体 → 看 BFCL、τ²-Bench、Terminal-Bench • 中文 → 看 SuperCLUE、OpenCompass
第三步:交叉验证,找矛盾点。对比"客观基准"和"人类偏好"两个流派的结果。如果一个模型在 HLE 上很强但在 LMArena 上平平,说明它"硬推理强但对话体验一般";反之则说明它"讨人喜欢但深度推理弱"。矛盾点恰恰能告诉你这个模型的真实性格。
第四步:做一次自己的"私有测试"。这是最被低估、却最有价值的一步。用你自己实际工作中的几个真实任务去测这个模型——你最关心的那种 bug、你常写的那种文档、你常问的那种问题。模型见过公开基准的题,但绝对没见过你的私有任务。你的私有测试结果,优先级高于任何公开榜单。
第五部分:如何用榜单做选型参考
确认了能力之后,选型还要考虑能力之外的因素。给你一个完整的选型清单。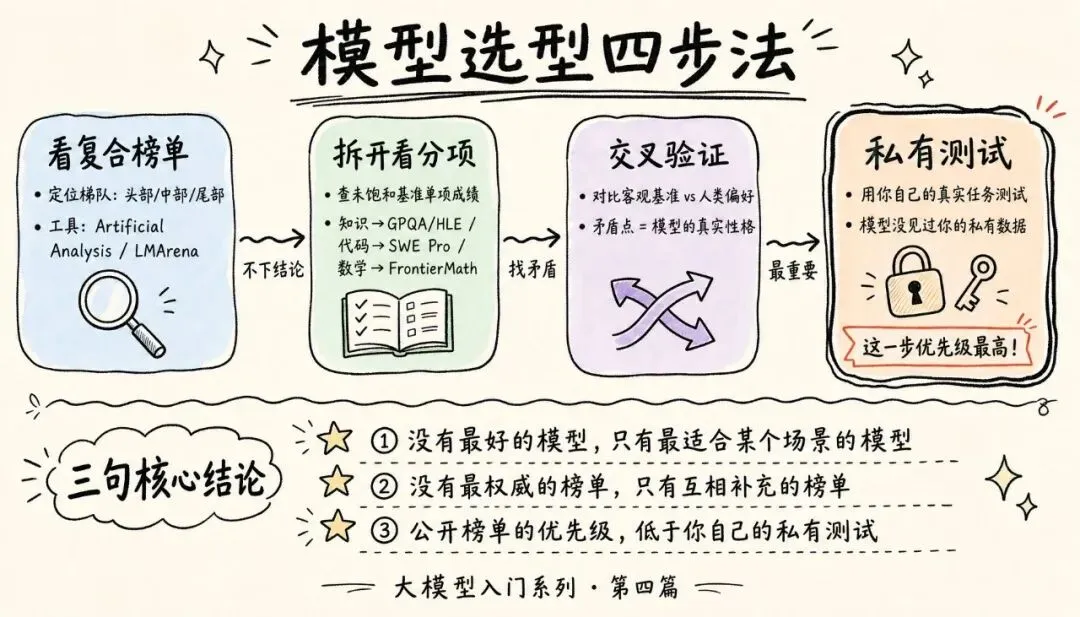 1. 先明确你的主场景,再去对应的榜单。不要追求"全能冠军":
1. 先明确你的主场景,再去对应的榜单。不要追求"全能冠军":
• 写代码 / 做开发 → 重点看代码类榜单 • 做 AI 助手 / 自动化工作流 → 重点看智能体类榜单 • 中文内容创作 / 客服 → 重点看 LMArena 创意写作分项 + SuperCLUE • 科研 / 复杂分析 → 重点看 GPQA Diamond、HLE
2. 能力之外的四个硬指标,Artificial Analysis 这类榜单会一并提供:
• 成本:每百万 token 的价格。顶尖模型之间能力差距在收窄,成本往往成为决定性因素。 • 速度:每秒输出多少 token。做实时交互应用时很关键。 • 延迟:首个 token 返回的时间。 • 上下文长度:模型一次能处理多长的输入。处理长文档时很重要。
3. 注意"顶级模型差距正在收窄"这个趋势。2026 年的公开数据显示,综合榜前 10 名的模型分差往往不超过 50 分。但更根本的原因不只是"分差小"——而是前面讲过的置信区间重叠:头部模型的误差范围互相覆盖,在统计意义上它们其实分不出明确高下。所以对大多数人来说,纠结榜单第 1 名还是第 5 名意义不大,场景匹配度、成本、生态(是否支持你需要的工具、是否有好的 SDK)更值得花精力。
4. 开源 vs. 闭源也是一个选型维度。闭源模型(Claude、GPT、Gemini 等)通常榜单领先、开箱即用;开源模型(DeepSeek、Qwen、GLM、Kimi 等中国模型)在性价比、可私有部署、数据可控性上有优势。如果你有数据隐私或成本敏感的需求,开源模型值得认真评估。
5. 别忘了"时效性"。大模型平均每 1–3 个月就有重大版本更新,榜单排名变化极快。任何榜单数据都有保质期,建议每季度重新核对一次。本文档的数据截至 2026 年 5 月,你看到它时请留意是否需要更新。
总结
记住三句话:
1. 没有"最好的模型",只有"最适合某个场景的模型"。 选型从明确你自己的场景开始。 2. 没有"最权威的榜单",只有"互相补充的榜单"。 客观基准(看对错)和人类盲测(看体验)必须结合,饱和的基准(MMLU、HumanEval、GSM8K)基本可以忽略。 3. 公开榜单的优先级,低于你自己的私有测试。 榜单帮你缩小范围,最终决定权交给"用你的真实任务测一遍"。
主流榜单速查表:
「大模型入门」系列导航
本系列从硬件到模型,逐步带你建立大模型落地的完整认知。
已发布
1. 大模型推理精度与显存估算指南 2. 大模型推理速度、显存带宽与显卡选型指南 3. 大模型不同模型格式入门指南 4. 大模型评测榜单解读及模型选型指南(本篇)
后续计划
5. 大模型推理引擎横向对比与选型参考 6. 大模型推理性能测试及指标解读
...
觉得有用的话,欢迎“点赞👍”、“转发”、“收藏”。
数据来源:LMArena、Artificial Analysis、SWE-bench(Epoch AI / Scale AI SEAL)、Humanity's Last Exam(Center for AI Safety / Nature 2026)、OpenCompass、SuperCLUE 等公开榜单,数据快照时点为 2026 年 5 月。大模型迭代极快,建议每季度重新核对榜单排名与最新得分。
