💎 硬通货:解锁了OceanBase、MySQL、OpenGauss、金仓、崖山、 KaiwuDB、TiDB、翰高、GBase、Neo4j、NebulaGraph、东方通…等十几家数据库的官方认证(算是解锁了“专业皮肤”)。
🏅 社区身份:OceanBase 社区 版主 及 布道师,获评墨天轮 MVP、崖山 YVP、KaiwuDB MVP、金仓 KVA、TiDB MVA、NebulaGraph 、IFClub等社区的“伙伴”,各大征文赛场常"刷榜",奖杯攒了一箩筐。
✍️ 输出基地:文章常驻公众号、墨天轮、ITPUB、CSDN 首页推荐。在这里,我把复杂技术翻译成你能懂、能用的“攻略”。
📌 前言
上个月那篇“反焦虑”思考承蒙大家厚爱,被顶上热搜。当时我就说,排行榜有趣的可不只是那几个数字,而是数字背后暗藏的“玄机”——哪家在默默赚钱,哪家在筹备大招,又有哪家偷偷换了赛道。
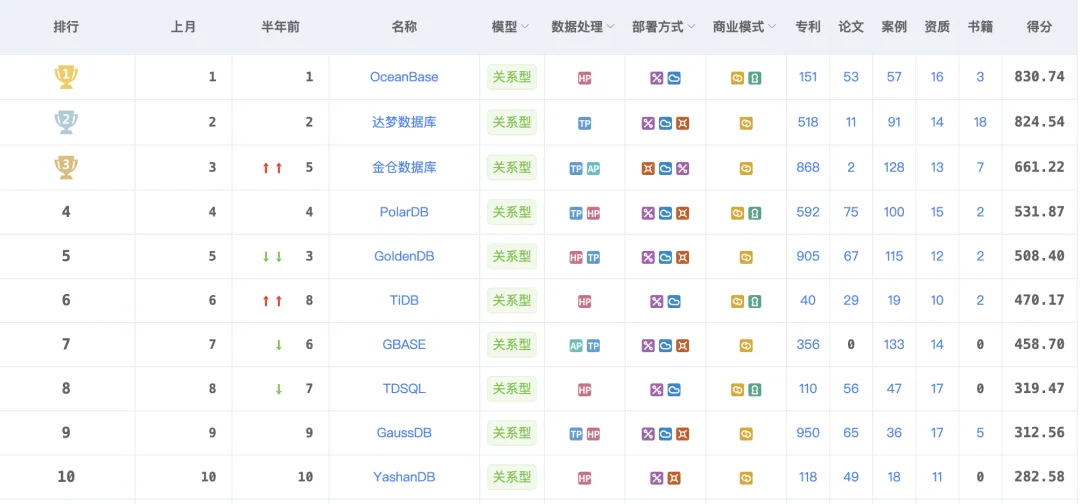
这不,五月数据一公布,我就知道又有热闹可瞧了:OB 以 830.74 分继续霸榜,达梦 824.54 分紧随其后,双双突破 800 分大关。金仓稳稳守住第三,前十强的阵容那叫一个雷打不动。但真正让我兴奋得搓手手的,是榜单深处的“暗流涌动”——AI 与数据库的关系,正从“外挂插件”升级为“底层基因”。更要命的是,AI 能力竟成了留在牌桌上的隐形“入场券”。有人欢呼这是“智算革命”,也有人冷笑不过是新瓶装旧酒。
作为一枚在数据库圈上新的老登儿,这期咱接着唠,好好掰扯掰扯这些变化。
一、🥇 第一梯队:八百岳上双雄会,分数涨得有门道
🔥 OceanBase:830.74 分 | 达梦:824.54 分 | 双破 800 大关
先瞧瞧头部这俩“狠角色”。OB 以 830.74 分继续霸榜,达梦 824.54 分紧紧跟随。这俩的分数走势,活脱脱像绑在一起的助推火箭啊!上个月刚双双突破 700 分,这个月又齐刷刷跨过 800 分门槛。一个月就涨了快一百分,这速度在国产数据库圈,比我家楼下便利店补货还麻溜。
不过咱得分清楚,这分数暴涨可不是“注水”,而是实打实的生态加速。OceanBase 这个月在社区治理上那是动作不断——不仅发布了 seekdb M0 插件,为 AI Agent 框架 OpenClaw 打造“外部记忆中枢”,还在 ICDE 2026 国际顶级数据库会议中多篇论文入选工业赛道与研究赛道。达梦则是直接扔出 DM9 重磅发布,用同一套内核代码实现集中式与分布式的深度统一,彻底终结了架构选型的“选择困难症”。
图片来源于墨天轮:
内容为排行榜前十数据库产品的得分详情。
1.1 💡 关于品牌分:它到底是“虚”的还是“实”的?
品牌分这玩意儿,说白了就是衡量综合影响力的,像搜索热度、社区活跃度、技术内容产出量等都在考量范围内。你就把它当成数据库圈的 “大众-点评”——分高不代表技术就是天下第一,但至少说明“大家最近都在热议你”。
长期霸榜的选手,基本上在“技术硬实力”和“品牌软实力”这俩维度都没啥短板。这一点,十强选手们用一年多的稳定表现已经证明得明明白白了。
1.1.1 🔒 前十格局为何“焊死”了?
从排行榜发布到现在,前十名的阵容已经相当固定了。金仓稳坐第三,PolarDB、TiDB、GaussDB、AnalyticDB、openGauss、GBase、TDengine 等依次排列。
这种稳定性背后可是有信号的:国产数据库的“战国时代”快要结束咯,第一梯队的格局基本成型。新玩家想挤进前十,难度就好比用单核 CPU 跑大模型——理论上不是不行,但实际操作起来,那可得脱层皮。
二、⚡ 趋势深水区:AI 正在从“贴牌合作”走向“内核共生”
2.1 🔬 行业观察:AI 和数据库的关系变了
这部分可是本期解读的重点,我可得好好唠唠。
去年大家还在争论“数据库到底要不要集成 AI”,今年这问题就变成 “怎么集成才能丝滑不拧巴” 。排行榜上的变化只是表面现象,深层的趋势是:AI 和数据库的融合,正从“外部适配”迈向“内核共生”。
2.2 🧠 分数狂飙,凭的是“数据库长出 AI 脑子”
OB 和达梦这次齐刷刷冲上 800 分,表面看是传统豪强的胜利,骨子里却是 AI 能力的一次集中爆发。
OceanBase:让数据库学会“边查边想”
在金融风控这类争分夺秒的场景里,OB 的向量检索能力已经像老司机认路一样纯熟。通过混合检索和零开销压缩技术,海量特征匹配的延迟大幅压缩,让 AI 拥有了生产级的持久化记忆层,彻底解决了大模型“断电即失忆”的痛点。通俗点说,这不是给数据库装了个“外挂搜索”,而是让它自己长出了“AI 海马体”。
达梦:优化器开始“自己写 SQL”了
DM9 集成的“设计智能体”和“运维智能体”,让数据库从“被动响应”转向“自我设计与自愈”。通过 AI 驱动的查询计划优化,达梦在电信级的 OLTP 场景下,CPU 资源消耗断崖式下降。以往得靠 DBA 熬夜调参的活儿,现在数据库自己就悄悄干了。难怪有同行调侃:“再这么进化下去,DBA 就要转型成 AI 的健身教练了——只需要监督它别‘练偏’。”
2.3 🛡️ 十强稳如磐石,因为 AI 成了标配
今年的前十榜单稳得让人想打哈欠,但这份“无聊”背后藏着一个残酷现实:没有 AI 加持的数据库,正在牌桌上悄悄被请离。
金仓:自带“老中医”诊断系统
别的数据库还在靠人力分析慢查询,金仓已经覆盖 14 省近 50 个公积金城市,并且拿下中国移动三年原厂维保的定向采购大单。其在 AI 方向的深耕也不含糊——强调“内核原生”的智能新标准,将向量能力深度融入数据库底层。运维效率的飙升,让半夜被报警电话吵醒的日子越来越少——这玩意儿,可比咖啡提神。
PolarDB:弹性伸缩学会了“看眼色”
在大促洪峰面前,PolarDB 的 AI 动态扩缩容,让资源利用率从“过得去”变成“真香”。以前预留一栋楼的服务器当保险,现在按需呼吸,企业 CFO 看了都想给数据库发锦旗。
GoldenDB & TiDB:各显神通的 AI 落地派
本月 GoldenDB 以 508.40 分位列第五,发布了向量版,成为国内首批具备“标量+向量+全文混合检索”能力的数据库,直接支持 RAG 场景。TiDB 则通过平凯数据库云服务实现了秒级扩缩容,一体化融合了 HTAP、向量存储与全文索引,拿下杭州银行 1053.75 万元采购大单。
十强选手们用行动证明了一件事:AI 已经不是加分项,而是参赛资格证。 没有这个“智算引擎”,连前十的边儿都摸不着。
2.4 🎯 十强之外的“特种兵们”同样能打
Top 10 之外,其实藏着不少专注垂直场景的“狠角色”。有些数据库生来就是为了解决特定问题的——比如搞云原生架构的、专注时序数据的、主攻实时分析的,在自己的专属赛道上混得风生水起,比大厂选手还滋润。
以 YashanDB 为例,本月成功卡位第十,不仅入选“2025 年度卓越软件项目案例”榜单最高级别——卓越级,还积极拥抱 AI,完成了从底层软件向“AI 应用孵化底座”的角色转型。这些“小而美”的产品虽然在整体分数上没法撼动头部格局,但在专业场景下的技术深度,那可值得关注。
三、🎯 未来竞争核心:AI 工程化落地与服务体系
3.1 🏗️ “AI 能力工程化落地”到底难在哪?
做个 Demo 和做出成熟产品之间的差距,那可大了去了,简直就像隔着一个太平洋。
很多数据库厂商的 AI 功能,演示的时候效果惊艳得让人下巴掉地上,可一到生产环境,就各种“水土不服”。当前部分产品展示的智能诊断、NL2SQL、自动调优等能力,在 POC 环境下表现可圈可点,但到了网络隔离、规则复杂、数据质量参差不齐的真实生产环境,效果往往难以复现。为啥呢?因为工程化可不是炫技,而是要解决一万种“奇葩”情况的能力——数据倾斜咋处理?节点故障怎么容错?混合负载场景下 AI 查询和普通查询咋调度资源?这些问题只要有一个没处理好,用户的体验就会从“哇塞”变成“哎呀妈呀”。
所以,AI 能力从“有”到“好用”,还有相当的距离。 厂商在对外宣传时,应对用户保持诚实,避免制造不切实际的预期。
3.2 🏰 服务体系:容易被忽略的隐性护城河
要是把 AI 能力比作数据库的“矛”,那服务体系就是“盾”。
国产数据库的竞争已经进入“深水区”啦——技术差距越来越小,产品功能也越来越像,最后拼的就是谁能真正帮用户把东西用起来。这就包括:文档质量、社区响应速度、技术支持水平、案例沉淀厚度。这些东西虽然不会体现在排行榜的分数里,但却实实在在影响着用户的续费率。
3.2.1 🌱 社区治理的“软实力”红利正在释放
像 OceanBase 的社区版主和布道师体系、TiDB 的开源社区运营、NebulaGraph 的开发者关系建设——这些“软投入”短期内可能看不到啥直接回报,但从长远来看,它们可是决定数据库能走多远的关键因素。开源大模型生态非常给力,也为数据库厂商降低 AI4DB 的落地门槛提供了关键助力。
四、📊 细数榜单:几家欢喜几家稳,守位之战已打响
📈 整体格局:稳重有变,暗流涌动
全面瞅瞅五月榜单,前十名的构成跟上月一毛一样,一个席位都没换。这种“稳定”背后有两层意思:一是头部数据库已经建立起竞争壁垒,追赶者短期内很难突破;二是市场进入“精耕细作”阶段,各家都在自己的地盘上深挖。
4.1 ⚠️ 中腰部选手:不进则退的压力测试
对于排名 11 - 30 的数据库产品来说,它们的处境比头部可要微妙得多。头部有品牌溢价,尾部有增长空间,可中腰部得在有限的市场关注度里抢份额。这个区间的排名波动往往最大——一次成功的社区活动,或者一场技术事故,都可能让名次大幅震荡。
4.2 🚀 新锐力量:找准生态位比追逐名次更重要
榜单后面出现了一些专注细分领域的新产品,如 TDengine、KaiwuDB、He3DB、RisingWave 等。它们分数不高,但技术定位很清晰——有的专攻边缘计算场景,有的聚焦隐私计算,有的做多模数据处理。对这些产品来说,与其在总榜上争名逐利,不如在自己的垂直赛道做到无可替代。大而全的时代已经过去咯,“专而精”才是新玩家的破局之道。