之前好奇为什么不直接移植 PC 游戏到手机端,最近刚好看到一个科普漫画,本文简单展开讲讲。
1、GPU
讲到游戏和 AI,那首先最重要的就是图形处理器(GPU)了,我们先从 GPU 讲起。
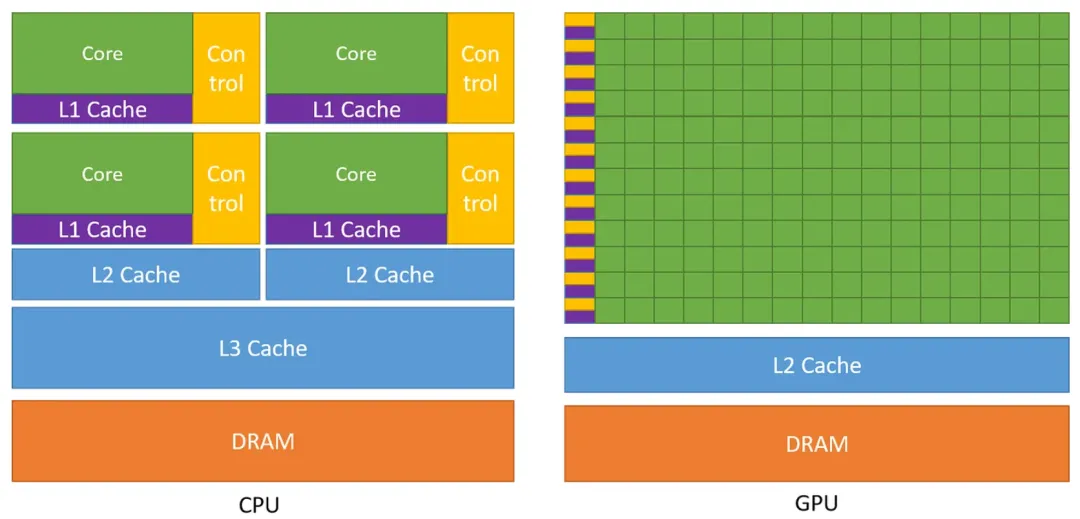
GPU 是单指令多线程(SIMT、Single Instruction Multiple Threads) 的实现,为大规模并行性和高吞吐量而设计,可以以非常快的速度执行大量线性代数和数值计算,但代价是中高等指令(分支处理指令等) 会有延迟(对比 CPU)。
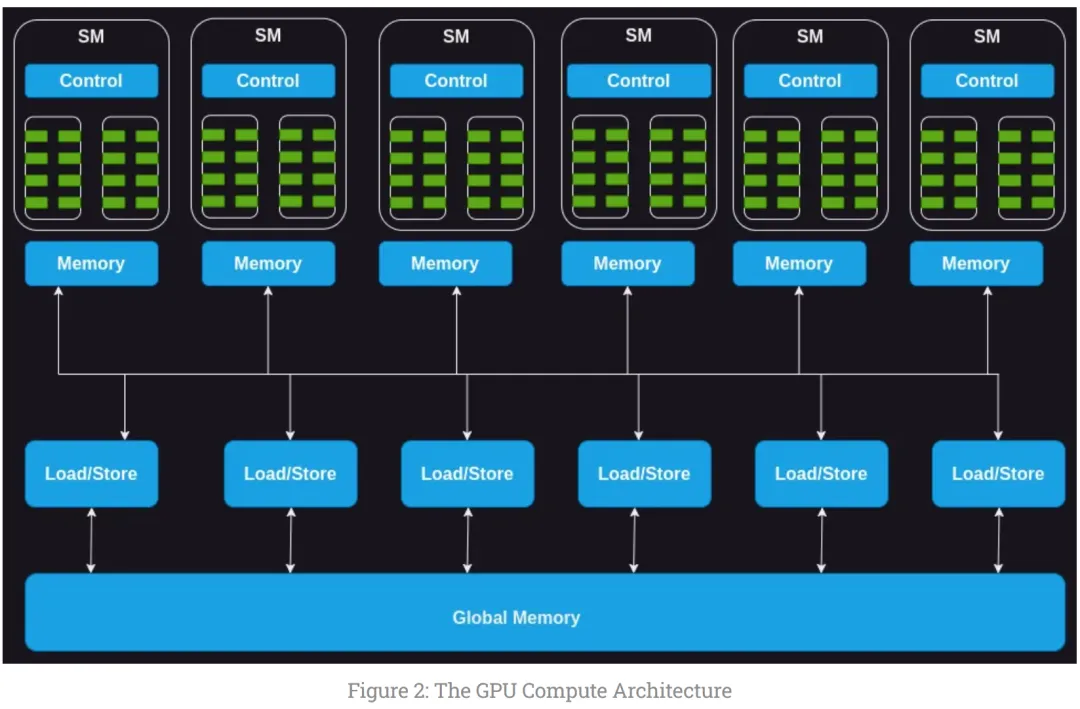
GPU 由一系列的流式多处理器(SM、streaming multiprocessors) 组成,每个 SM 上都有有限数量的 on-chip memory,在所有核中共享,共享的还有 SM 的控制单元。每个 SM 上都配备了基于硬件的线程调度程序来执行线程,还具有多个功能单元或加速计算单元,如张量核心或光线追踪单元,以满足特定工作负载的计算需求。
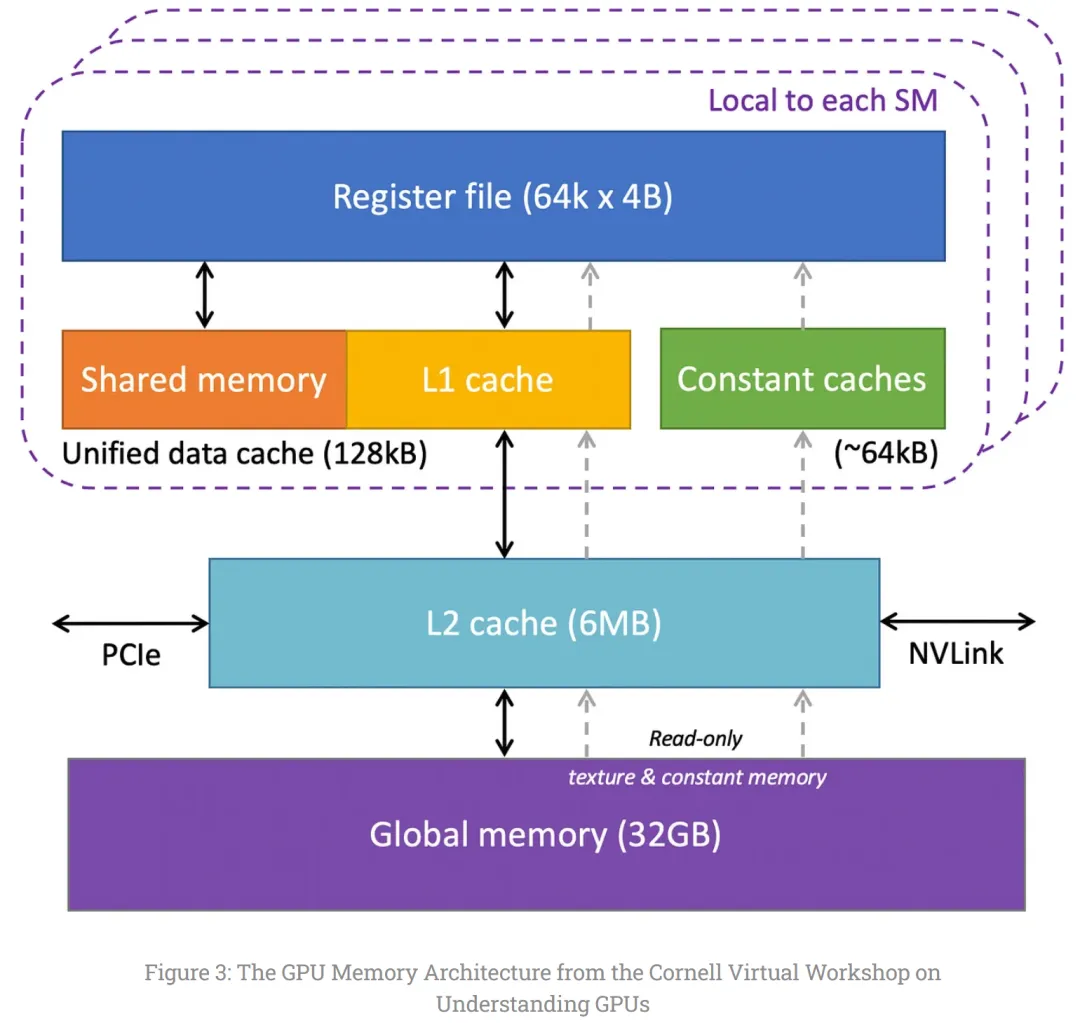
GPU 的内存架构如下,可以直接按图的字面意思来理解:
- Registers(寄存器)。每个 SM 中都有大量的寄存器,如 Nvidia A100 每个 SM 有 65536 个,寄存器由 SM 统一管理,动态分配给各线程,一旦分配即为该线程所私有。
- Constant Caches(常量缓存)。芯片上有常量缓存,缓存 SM 执行代码所使用的常量数据。
- Shared Memory(共享内存)。每个 SM 上有一个共享内存,为 SM 上的线程所共享,可作为数据同步机制。
- L1 Cache(L1 缓存)。每个 SM 上有一个 L1 缓存,缓存 L2 缓存中经常访问到的数据。
- L2 Cache(L2 缓存)。在外层,有一个 L2 缓存,由所有 SM 共享,缓存全局内存中经常访问到的数据。
- Global Memory(全局内存)。GPU 片外还有一个全局内存。
由于每个 SM 的线程都有自己的一组寄存器,所以这里的线程切换是 Zero-overhead Scheduling(无开销) 的。
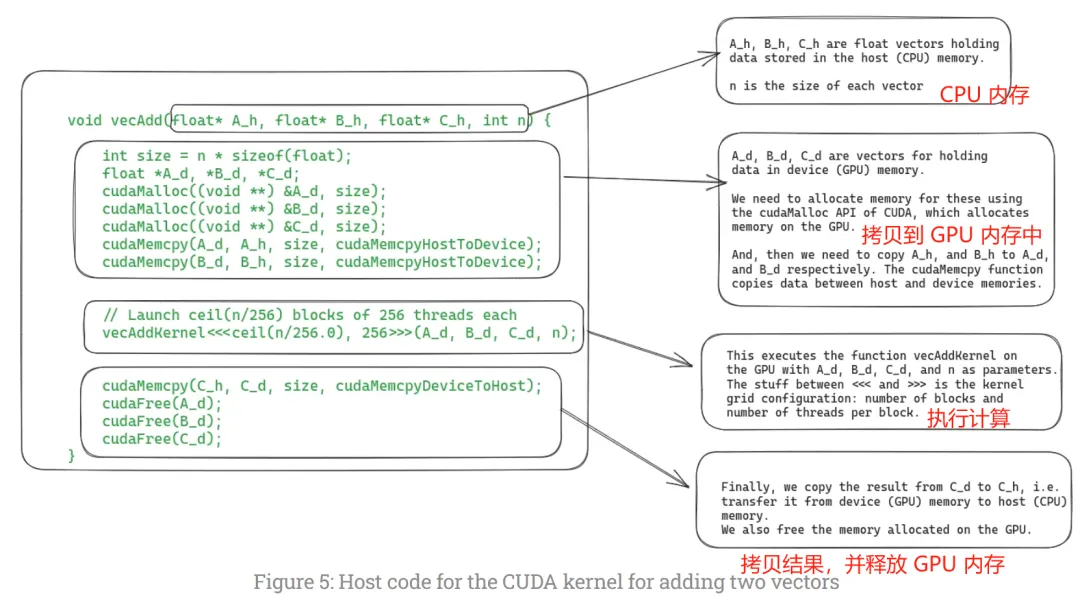
一个 CUDA 编码的案例(向量相加):
上图展示了在 PC 端用 CUDA 实现两个向量相加的完整流程:首先通过 cudaMalloc 在 GPU 显存中分配空间,再用 cudaMemcpy 将数据从 CPU 内存拷贝到 GPU 显存;然后以 ceil(n/256) 个线程块、每块 256 个线程的配置启动核函数(Kernel);计算完毕后,再通过 cudaMemcpy 将结果拷贝回 CPU 内存,最后释放 GPU 显存。这里显式的两次数据拷贝,正是 PC 端 CPU 与 GPU 各有独立内存(物理隔离,通过 PCIe 互联)的直接体现——在后文介绍移动端 UMA 架构时,我们会看到这一开销在移动端是如何被规避的。
GPU 根据资源可用性分配一个或多个块在 SM 上执行,一个块的所有线程都在同一个 SM 上分配和执行,这是为了利用数据局部性和线程之间的同步。
说明:本节中 SM、Shared Memory、CUDA 等术语均以 NVIDIA GPU 架构为参照系。移动端 GPU(如 ARM Mali、高通 Adreno、苹果自研 GPU)在硬件模块的命名和组织方式上有所不同,但同样遵循 SIMT 并行计算的核心原则。
2、PC 和 Mobile GPU 的区别
虽然移动端 GPU 使用和 PC 端 GPU 一样的 APIs,但是这两种 GPU 的架构是不太一样的。
2.1、PC GPU
在 PC 端,GPU 有强大的电源提供大量的电能,还有热管、风扇协助散热,不需要担心供电和能耗问题,拥有更宽的数据传输带宽。设计 PC GPU 时无需将能耗作为重要的限制条件。
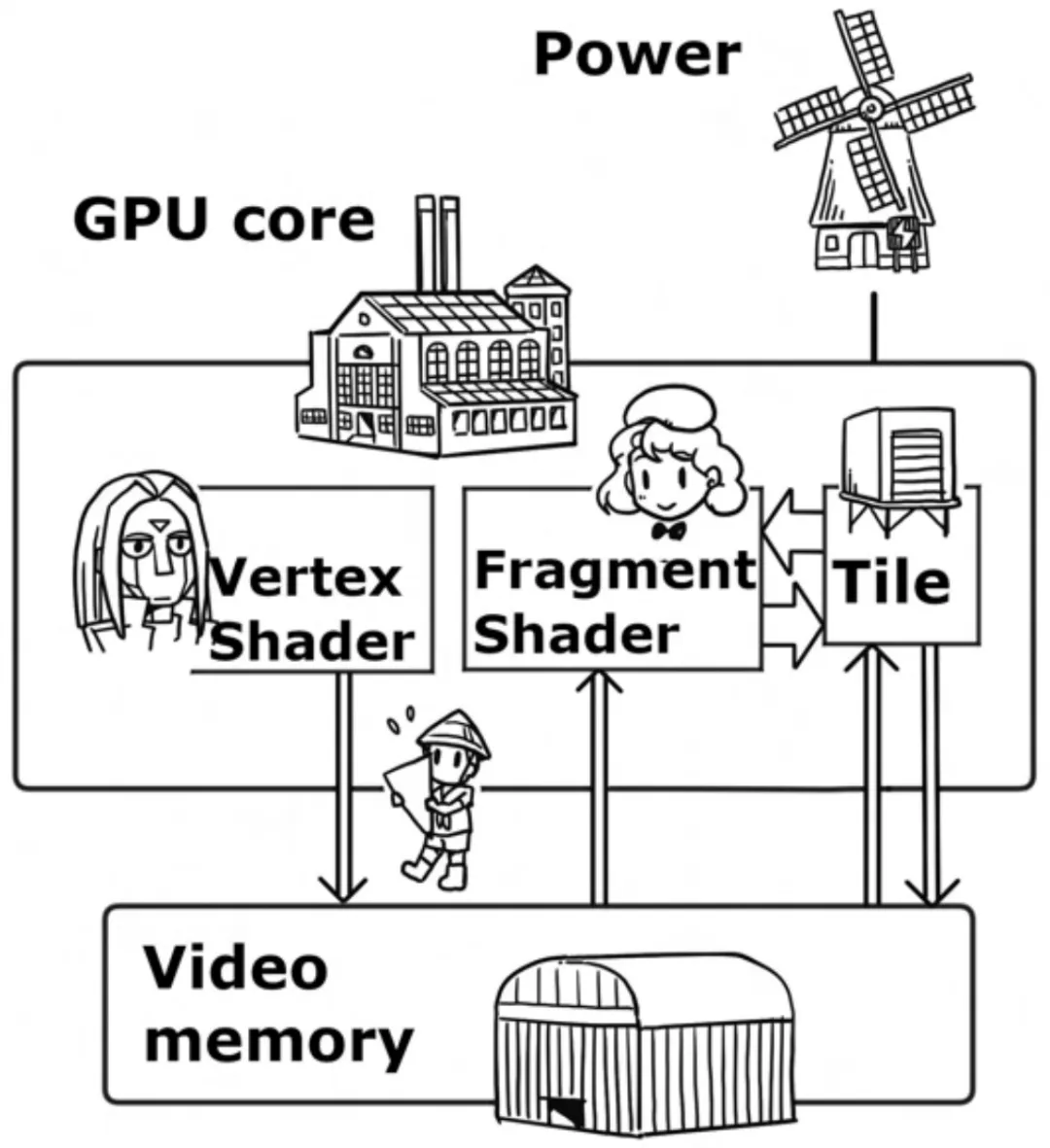
在三维图形渲染中,GPU 的计算核心需要不断地与显存(VRAM)交换顶点坐标、纹理贴图、颜色缓冲区和深度信息。待渲染的数据存储在显存中,由 GPU 核心读取并进行处理。
在 GPU 核心中,有两个主要的部分:
- Vertex shader(顶点着色器):处理所有待渲染的三角形。
- Fragment shader(片元着色器):接收 Vertex shader 传来的三角形,将其转换为片元(fragment)。
随后,片元数据写入显存中的帧缓冲区,最终图像便可显示在屏幕上。
桌面端GPU为了满足庞大的并行计算需求,采用了极度宽阔的显存位宽和超高频率的专用显存芯片。
这里有一个 PC 与移动端的根本性架构差异值得单独说明:独立内存 vs. 统一内存架构(UMA)。在 PC 平台上,CPU 拥有系统内存(DDR SDRAM),GPU 拥有独立显存(GDDR6X),两者物理隔离、通过 PCIe 总线互联——这也是 CUDA 代码中必须手动调用 cudaMemcpy 来回拷贝数据的根本原因。而在移动端 SoC(片上系统)中,CPU、GPU、NPU 等所有计算单元集成在同一颗芯片上,共享同一块物理内存(LPDDR5),这被称为统一内存架构(Unified Memory Architecture,UMA)。
UMA 的优势在于消除了 PCIe 总线传输开销,CPU 产生的数据(如游戏逻辑计算的顶点坐标)可以零拷贝地直接被 GPU 读取。但代价是这条共享总线必须同时服务于 CPU、GPU 以及其他模块,天然受限,带宽极为宝贵。这正是移动端必须精打细算每一字节带宽的根本原因,也是 TBDR 架构存在的核心动机之一。
2.2、桌面端的暴力美学——立即渲染模式(IMR)
在 IMR 架构中,当图形应用程序(通过 DirectX、Vulkan 或 OpenGL)将渲染指令提交给 GPU 时,GPU 采取的是“拿到什么就画什么”的即时处理策略。
在 IMR 的逻辑中,可以说是“进一个三角形,出一个三角形的像素;工作完成,概不负责”。这种设计在硬件实现上非常直观,硅片层面的逻辑控制相对容易设计,这也使得芯片架构师可以将海量的晶体管预算全部投入到计算单元(ALU)的堆砌上。
然而,IMR 架构存在一个致命的逻辑缺陷,即对场景深度与遮挡关系的“后知后觉”。在任何一个复杂的现代 3D 游戏(如《古墓丽影》或《赛博朋克2077》)中,玩家视野前方的物体总是层层叠叠的。假设在游戏场景中,摄像机前方依次存在一堵砖墙、墙后的一座高山,以及更远处的蓝天。如果游戏引擎按照“天空 -> 山峰 -> 砖墙”的顺序向 GPU 提交绘制指令,IMR 架构的执行过程将是灾难性的。
这种现象在计算机图形学中被称为“过度绘制”(Overdraw)。在上述例子中,同一个屏幕坐标的像素被着色计算了三次,显存也被来回读写了三次,但最终呈现在玩家眼前的只有最前方的砖墙像素。前两次庞大的计算量和显存带宽被彻底、无情地浪费了。
为什么桌面端 GPU 能够容忍如此巨大的资源浪费?答案在于“大力出奇迹”。诸如 RTX 4090 这样搭载了超大规模缓存(72MB L2 Cache)和高达 1008 GB/s 独立显存带宽的怪兽,完全有能力用海量的吞吐量强行掩盖过度绘制带来的效率低下。
2.3、移动端的精巧绝伦——分块延迟渲染(TBDR)
对于带宽仅有 68 GB/s 且功耗受到严酷限制的移动设备而言,传统的 IMR 流水线无疑是一条通往死胡同的绝路。
在移动端,受限于封装尺寸和散热条件,可用功耗远低于桌面端。如图所示,GPU 各模块间的传输链路有限,每次访问外部内存都会消耗大量能量,电池容量有限的移动设备根本无法承受频繁的外部内存访问。
为了彻底切断 GPU 片段着色核心对外部耗电极高的 LPDDR 内存的频繁访问,移动 GPU 架构师决定将高分辨率的屏幕“粉碎”成无数个微小的矩形区域,这被称为“分块”(Tiles)。
Mobile GPU 在 fragment shader 旁设置了 tile memory,移动端屏幕尺寸固定,整个屏幕可被划分成大量均等的 tiles,每个 tile 包含 16x16 ~ 64x64 的 fragments。
为何选择如此微小的尺寸?因为 16x16=256 个像素的颜色数据(Color Buffer)、深度数据(Depth Buffer)和模板数据(Stencil Buffer)的总和,其体积非常小巧,恰好可以完整地容纳在 GPU 着色核心(Shader Core)内部极速且低功耗的片上静态随机存取存储器(SRAM)中。
TBDR 将渲染流水线拆分为两个独立阶段。第一阶段(几何阶段):GPU 先将当前帧所有 Draw Call 的顶点数据全部处理完毕,将变换后的三角形位置及其所属分块的"分配信息"写入外部内存的专用区域,称为参数缓冲区(Parameter Buffer),这会引入一定的顶点数据回写开销。第二阶段(片段阶段):GPU 逐块处理,每个 tile 仅从参数缓冲区取出与之相交的三角形,在片上 Tile Memory 中完成最终着色,整块处理完毕后才一次性写回外部内存。参数缓冲区带来的顶点开销,相比片段阶段节省的帧缓冲读写量,几乎可以忽略不计。
仅仅将屏幕切块还不够,若不能解决“过度绘制”(Overdraw)的顽疾,即使是片上 SRAM 的能量也会被大量无意义的着色计算耗尽。这引出了 TBDR 中“D”(Deferred,延迟)所代表的核心技术精髓——隐藏面消除(Hidden Surface Removal, 简称HSR)。
在进入片段着色阶段前,由于 TBDR 的几何阶段(第一阶段)已经完整获取了整个场景的几何多边形分布,它不再像IMR那样“蒙眼狂奔”。针对每一个 16x16 的分块,由于 GPU 已经知道了这个微小区域内包含的所有三角形,它可以在片段着色器(Fragment Shader)真正开始计算颜色之前,在硬件层面对这个分块内的所有三角形进行精确到像素级的深度预判。
这是一种完美的基于硬件的射线追踪思维。如果在这个 16x16 的分块内,前方的砖墙多边形完全遮挡了后方的山峰多边形,HSR 硬件电路会在山峰的像素进入高功耗的片段着色器计算其纹理和光照之前,直接将其无情地丢弃(Discard)。tile memory 可以减少要传输的 fragment 数据。而且如果 GPU 发现有三角形被其他三角形遮挡了,那么该三角形就可以直接丢弃掉,不需要绘制,直接在内存中处理完成,节省了带宽和能耗。
HSR 技术的伟大之处在于,它是完全“顺序无关”(Submission Order Independent)的。
目前主流移动端 GPU 在架构选择上各有侧重:Imagination Technologies 的 PowerVR 是 TBDR 的先驱和核心专利持有方,苹果自研 GPU 深度继承了这一架构路线;ARM 的 Mali 采用 TBR(Tile-Based Rendering,分块渲染),具备分块优化但无完整硬件 HSR;高通的 Adreno 则采用自研的 Flex Render 技术,可根据负载在 TBR 与 IMR 之间动态切换,灵活性更高。
2.4、殊途同归——桌面端的分块探索
随着桌面游戏画质向 4K 甚至 8K 分辨率的迈进,复杂光照计算和天文数字级别的多边形数量(即使是桌面端那高达 1008 GB/s 的 GDDR6X 带宽)也开始显得捉襟见肘。无节制地拓宽显存总线会带来巨大的封装成本和难以压制的废热。
在此瓶颈下,桌面显卡的双雄—— NVIDIA 与 AMD,不约而同地将目光投向了移动端已经演进成熟的“分块(Tiling)”哲学。
早在 2014 年的 Maxwell 架构(例如 GTX 980Ti 和神卡 GTX 750Ti)以及随后的 Pascal 架构(GTX 1080)中,NVIDIA 就已经悄然摒弃了传统的全屏立即光栅化,转向了一种名为“分块立即模式光栅化”(Tile-Based Immediate-Mode Rasterization, 简称 TBIM)的混合型渲染技术。
NVIDIA 的几何计算(包括曲面细分 Tessellation 和顶点着色)仍然是流水线式的立即模式。但在光栅化阶段,硬件会动态地评估工作负载,将屏幕切割成合适尺寸的区块,并确保同一区块内的多边形被集中光栅化和输出。
3、回到最初的问题
为什么不能直接把 PC 游戏移植到手机端?经过以上分析,答案已经呼之欲出。PC 游戏的整套制作管线——从美术资产的制作规范、Shader 的复杂度预算到渲染指令的提交顺序——都是围绕 IMR 架构和独立大带宽显存来设计的。将其搬到移动端,会遇到多重结构性障碍:
- 渲染管线假设不兼容:PC 游戏常用的 Alpha Test(透明度测试)、Framebuffer Fetch 等操作,会打断 TBDR 的 HSR 流程,强迫 GPU 提前执行片段着色,让精心设计的遮挡剔除完全失效。
- 带宽预算天壤之别:PC 游戏可以随意消耗 1008 GB/s 的独立显存带宽,而移动端共享 UMA 总线仅有数十 GB/s,还要与 CPU 竞争。高分辨率纹理、MSAA 等特性一旦直接照搬,带宽立刻崩溃。
- 功耗墙:桌面 GPU 的典型功耗在 200~500W,移动 SoC 的 GPU 功耗预算往往不超过 5W,相差百倍。
- Shader 复杂度:PC 游戏大量依赖几何着色器(Geometry Shader)、曲面细分(Tessellation)等在移动端 GPU 上支持有限或性能极差的特性。
因此,移植工作从来都不是"换个平台重新编译",而是需要针对 UMA 带宽约束、TBDR 渲染管线和严苛的功耗预算,对资产、Shader 和渲染技术进行系统性重构。
参考
- how-does-a-mobile-gpu-work
- How does a mobile GPU work? [pdf]
- What Every Developer Should Know About GPU Computing
- Tile-based Rasterization in Nvidia GPUs
- GPU Survival Toolkit for the AI age: The bare minimum every developer must know
- Hidden Surface Removal Efficiency
- Does Tile-Based Deferred Rendering have a place in Desktop?
- On NVIDIA's Tile-Based Rendering