概述
这张全球大模型排行榜,表面上是在排“谁最强”。但对普通用户来说,更重要的问题其实是:你每天用的那个 AI,到底是不是榜单里的那个档位?它适不适合你手上的任务?
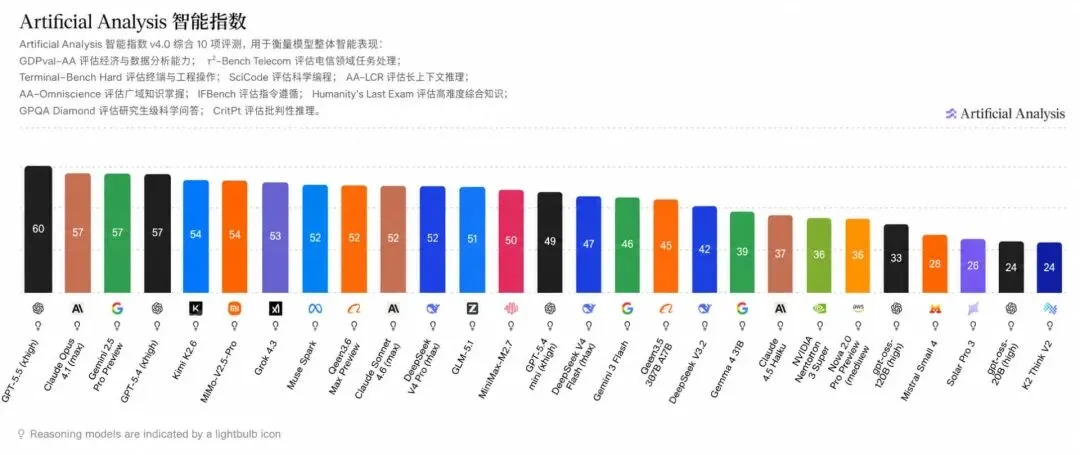
Artificial Analysis 最新的 Intelligence Index 里,GPT-5.5 拿到 60 分,排在第一。后面几个模型追得很紧:Claude Opus 4.7、Gemini 3.1 Pro Preview、GPT-5.4 都在 57 分左右。
再往后,Kimi K2.6、MiMo-V2.5-Pro 是 54 分,Grok 4.3 是 53 分,Muse Spark、Qwen3.6 Preview、Claude Sonnet 4.6、DeepSeek V4 Pro 等模型也在 52 分附近。
这组分数最有意思的地方,不是 GPT-5.5 排第一,而是头部模型之间的差距已经没那么大了。
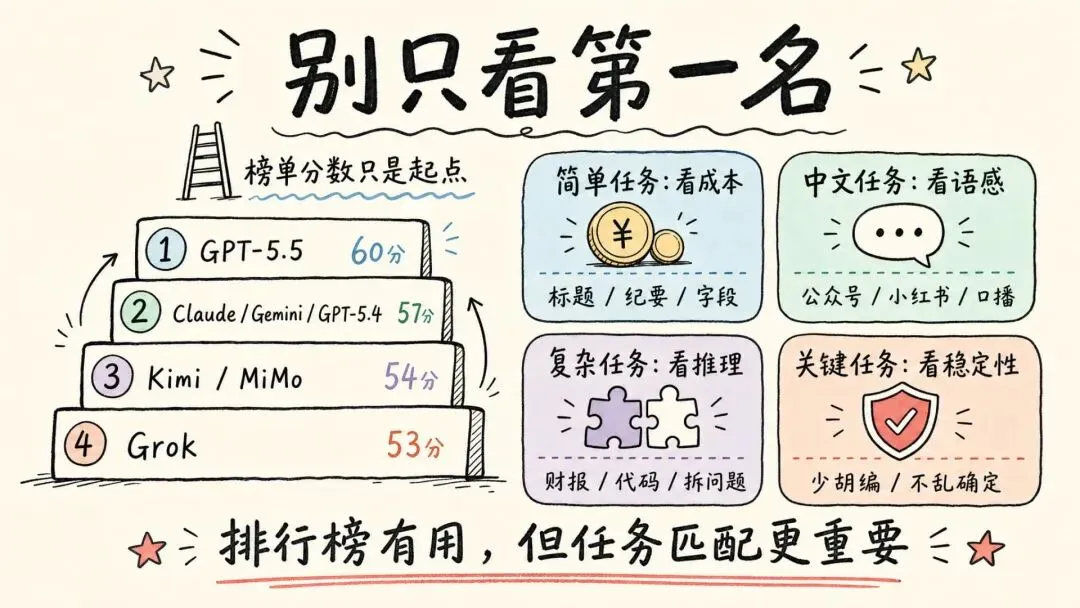
过去选模型很简单:谁最强就用谁。
现在不行了。写标题、改文案、整理会议纪要、提取字段,这些任务不一定非要第一名。你用最强模型,可能只是多花钱、多等时间。
但如果是读财报、拆商业问题、写复杂代码、跑长链路 Agent,模型能力差一点,结果可能就会偏很多。它会不会抓重点,会不会胡编,会不会把“不确定”写成“确定”,这些才是第一梯队真正值钱的地方。
所以这张榜不是用来膜拜第一名的。
它更像一张提醒表:哪些任务值得用贵模型,哪些任务用快模型就够。
排行榜解释:各模型优缺点,国内模型仍需努力
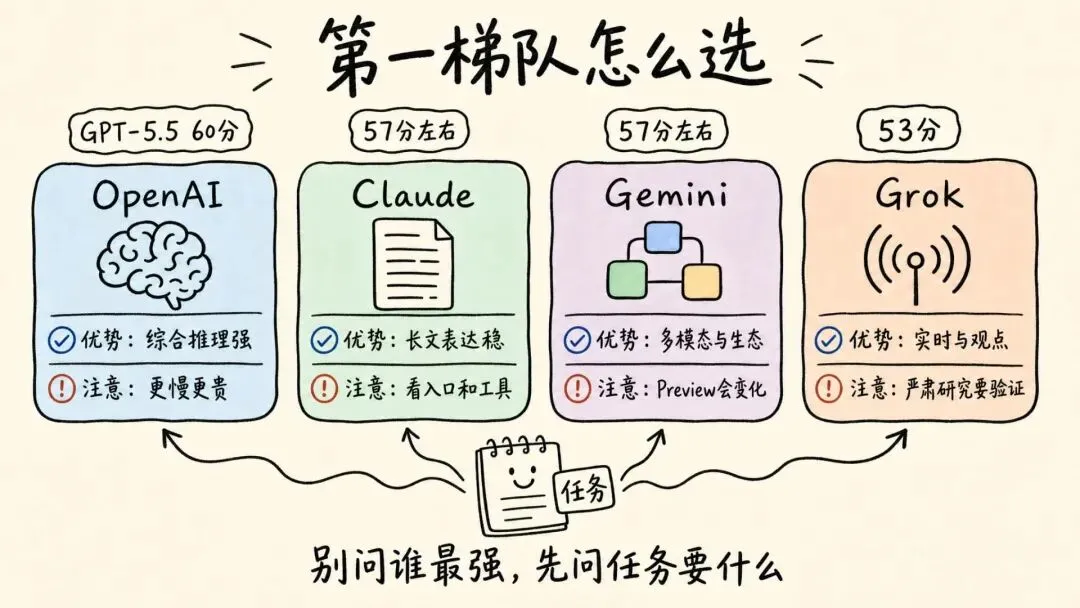
OpenAI:第一梯队里的强与贵
先说 OpenAI。
GPT-5.5 这次排第一,说明它在综合推理、知识、代码和真实工作任务上都很能打。适合复杂分析、长链路 Agent、代码重构、严肃决策这类高风险任务。
但它的缺点也明显:强推理通常意味着更慢、更贵,也不是每个入口都能稳定调用到这个档位。你说“我在用 ChatGPT”,不等于你每次都在用榜单上的 GPT-5.5。
GPT-5.4 也在第一梯队。它的问题不是不强,而是当 GPT-5.5 已经站到第一,5.4 更像一个稳妥但不再最顶的选择。对大多数复杂任务仍然够用,但如果是极限推理,用户自然会想上更高档。
Claude:长文和表达稳定
Claude Opus 4.7 的优势,是长文本理解、复杂表达和推理稳定性。它适合写长稿、分析文档、处理需要语气和逻辑兼顾的内容。
它的短板在于,具体体验很依赖产品入口、速度、价格和工具生态。如果你要做大量自动化、代码代理、联网检索,不能只看榜单分数,还要看它在你的工作流里顺不顺。
Gemini 与 Grok:生态、实时与边界
Gemini 3.1 Pro Preview 也在前排。Gemini 系列的优势通常在多模态、长上下文和 Google 生态相关能力上。适合处理大资料、跨格式信息、搜索和办公场景。
但它带着 Preview,这意味着体验可能还在变化。预览版模型冲榜很正常,真正落到日常工作里,还要看稳定性、速度和产品开放程度。
Grok 4.3 排在 53 分附近,说明它不是边缘选手。它的优势更偏向实时信息、社交语境和强观点表达。但如果拿它去做严肃研究、长文档精读或复杂企业流程,仍然要看具体能力边界。
国内模型:已经不是陪跑,但仍需追
再看国内模型。
Kimi K2.6 和 MiMo-V2.5-Pro 都到了 54 分,已经非常接近第一梯队。Qwen3.6 Preview、DeepSeek V4 Pro、GLM 5.1 也都在中高位。
这个信号很清楚:国产模型已经不是陪跑了。
做中文内容、中文办公、资料整理、自媒体写作时,国内模型有自己的优势。它们更懂中文语境,产品入口也更贴近国内用户,价格和响应速度往往更容易接受。
尤其是自媒体场景。写公众号、小红书、口播稿,不只是考逻辑,还考中文段落节奏、情绪分寸和“别太像报告”的感觉。这些东西,英文榜单分数很难完全体现。
但也要说句实话:国内模型仍需努力。
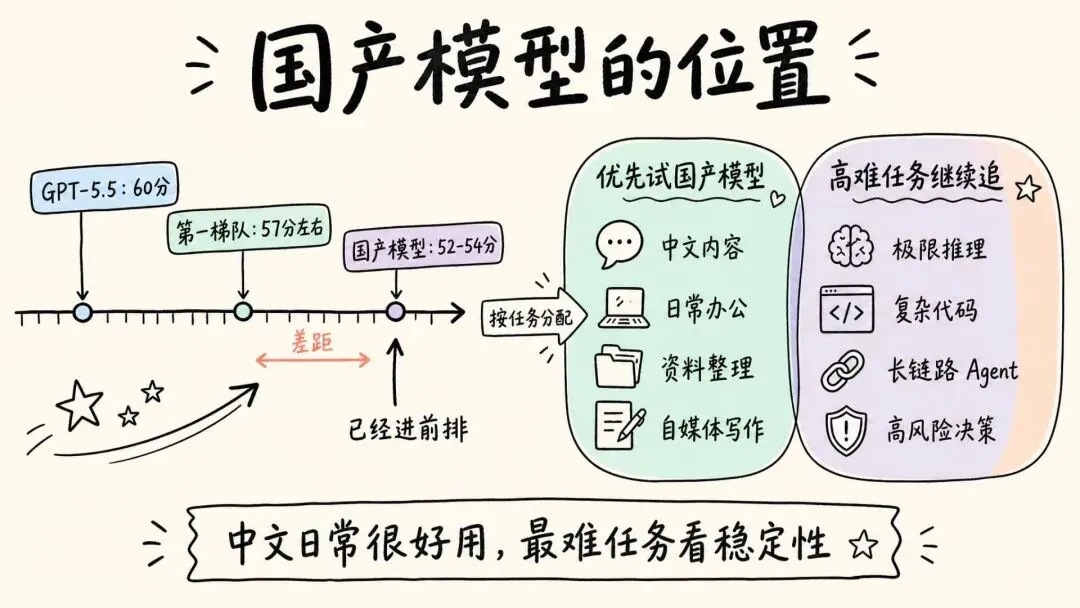
从这张榜看,国产模型已经能冲到 52-54 分这一档,但离 GPT-5.5 的 60 分仍有差距。差距不只是几分,而是极限推理、复杂代码、长链路 Agent、跨领域综合判断这些高难任务里的稳定性。
换句话说,国产模型在很多中文日常场景已经很好用,但在最难的任务上,还需要继续追。
所以我不会简单说“国产模型已经反超”,也不会说“只能用海外模型”。
更准确的判断是:中文内容和日常办公,国产模型值得优先试;复杂推理和高风险决策,第一梯队海外模型仍然更稳。
你平时用的是什么模型
这张榜看完,真正该问的不是“谁排第一”,而是“我平时到底在用什么模型”。
很多人以为自己在用最强模型,其实只是用了同一个品牌下的普通档位。
模型入口里的高推理、高性能等档位标识,不是装饰。它们往往代表更高推理预算、更强能力,也可能代表更慢和更贵。
所以你要看清楚几个问题:
- ◆你当前入口实际调用的模型是哪一个?
- ◆有没有开启高推理模式?
- ◆上下文长度够不够?
- ◆是否支持文件、联网和工具调用?
- ◆速度和价格能不能接受?
如果你只是改标题、润色短文案、整理会议纪要,不一定非要 GPT-5.5。用 Kimi、Qwen、DeepSeek、GLM 这类模型,可能更快,也更便宜。
如果你要做投研分析、论文理解、复杂代码重构、商业判断,那就别省模型。第一梯队模型加高推理档位,才更稳。
我自己的建议是,别迷信榜单,也别完全不看榜单。
你可以拿真实工作里的 5 个任务做一次小测试:
- ◆一篇文章改标题
- ◆一段口播稿润色
- ◆一份 PDF 摘要
- ◆一组数据解释
- ◆一个复杂问题拆解
让几个常用模型跑同样的问题,看谁最少胡说,谁最懂你的语气,谁最少让你返工。
这个测试,比盯着榜单争第一名有用。
大模型排行榜还会继续变。今天 GPT-5.5 第一,过段时间可能又有新模型冲上来。
但选模型的方法不会变:
简单任务看成本,中文任务看语感,复杂任务看推理,关键任务看稳定性。
你平时主力用的是哪个模型?评论区可以说说你的真实体感。