LMArena 600万+盲测 · 15家模型横评 · API性价比实测
事情是这样的。前几天我在做一个项目,需要调几个大模型的API做对比测试,就顺手查了一下各家最新的定价和排名。
结果不查不知道,一查直接愣住了。LMArena四月的榜单上,国产模型集体上位,而且API价格差距大到离谱。
GLM-5.1,Elo 1471。
开源模型第一,SWE-bench Pro 超过 Claude Opus 4.6,API价格不到它的四十分之一。
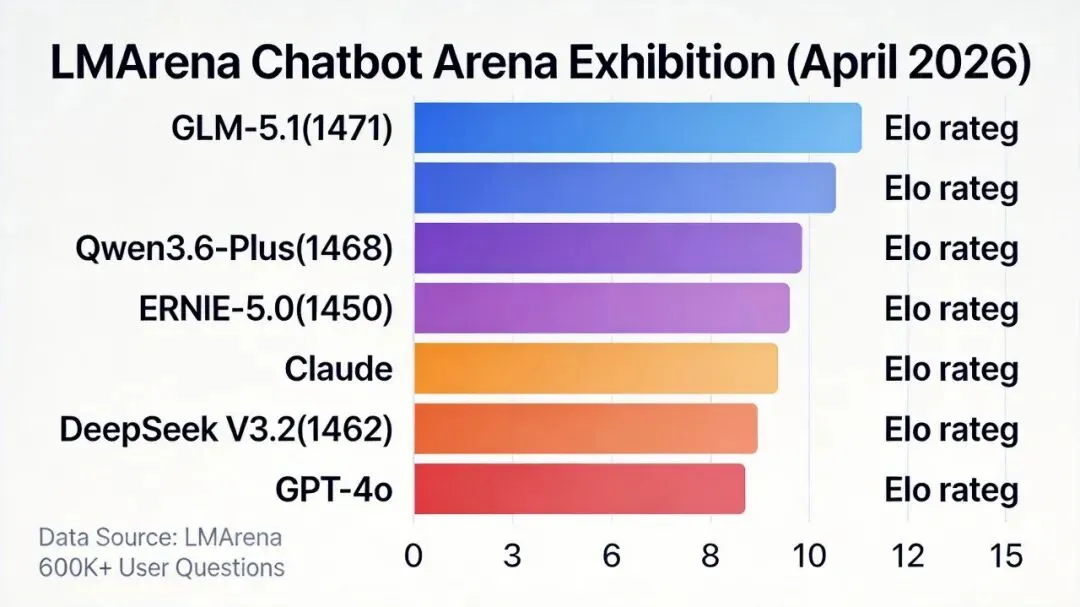
LMArena Chatbot Arena 四月排名变动
坦率的讲,我一直觉得排行榜这东西看看就行,别太当真。但这次LMArena的变动确实有点东西。
LMArena的Chatbot Arena你们应该不陌生,就是那个600多万人参与盲测的排行榜。你扔一个问题过去,两个匿名模型回答,你选哪个好。纯靠人类主观判断堆出来的分数,比那些固定benchmark更接近真实体感。
四月这一期,最大的变化就是国产模型集体上位。智谱的GLM-5.1拿到1471的Elo分,全球第13,开源模型里排第一。阿里的Qwen3.6-Plus在Code Arena编程排行里冲到全球第二,仅次于Claude。
说真的,GLM-5.1这个模型我关注了很久。745亿参数,基于DeepSeek-V3架构,MIT协议开源。最让我惊讶的不是它排第几,而是它在SWE-bench Pro编程测试里拿了58.4%,直接超过了Claude Opus 4.6的57.3%。
你想想看,一个开源模型,在编程这个Claude的传统强项上,把Claude超了。
很多朋友可能不知道,GPT-4 Turbo在中文能力评测里已经掉出了前100名。半年前它还是很多人眼里的天花板,现在连SuperCLUE中文榜的尾灯都看不见了。
我跟你说,这不是某一个模型突然爆发,是整个国产阵营在集体往上拱。从GLM到Qwen到DeepSeek到文心,每一个都在自己擅长的方向上捅破了天花板。
回到性价比这块。怎么说呢,排行榜好看归好看,但真正到了掏钱的时候,才是考验良心的时候。
我把各家API的定价拉出来做了一个「每美元能力值」的计算。方法很简单,拿Elo分数除以每百万token的输出价格,看一块钱能买多少能力。
DeepSeek V3.2 的每美元能力值是 Claude 的 50 倍
基于 LMArena Elo ÷ 每百万token输出价
| 模型 | 输出价 $/M tokens | 每$能力值 |
|---|
| DeepSeek V3.2 | $0.38 | 2391 |
| Gemini 3 Flash | $3.00 | 491 |
| Qwen3.6-Plus | $0.50 | 2936 |
| Claude Opus 4.6 | $75 | 48 |
太离谱了。你花一块钱用DeepSeek能搞定的事,用Claude得花五十块。
我自己也还在摸索这个平衡。不是说Claude不好,它确实在复杂推理和长文本分析上有一手。但问题是,你日常80%的调用根本用不到它贵出来的那点能力。写个文案、做个总结、改改文档,DeepSeek V3.2完全够了。
贵模型当手术刀用,便宜模型当瑞士军刀用。这才是正确的省钱姿势。
你如果感兴趣的话,可以试试Google的Gemini 3 Flash。Elo 1474,排名第11,比GLM-5.1还高,输出价才$3.00。被严重低估的一个选择。
我自己的感受是,选模型这件事就跟选工具一样。不存在一个模型打天下的情况,至少现在还没有。
文案写作、信息整理、简单编程、日常对话。性价比天花板。
还有一个我觉得挺重要的点。Qwen3.6-Plus在Code Arena全球第二,编程能力仅次于Claude。如果你的主要需求是写代码,这个模型可能比Claude性价比高得多。
我自己现在的做法是,日常调API先走DeepSeek V3.2,遇到搞不定的复杂任务再切Claude。这么做不是为了省那几毛钱,而是因为便宜模型响应快、并发高,体验反而更好。
✅ 实用建议 个人开发者和小团队,日常调用先走DeepSeek V3.2或Qwen3.6-Plus,复杂任务再切Claude。一个月下来API费用能省80%以上。
我始终觉得,追排行榜第一没有意义。你用模型是为了解决问题,不是为了发朋友圈说你在用全球第一的模型。找到那个能力够用、价格合理的,才是正事。
说到底,排名好看有什么用,钱包才最诚实。
这个四月最大的变化不是谁排第一,而是国产模型终于把「又便宜又好用」这件事坐实了。以前是便宜但不好用,现在是便宜还好用。想想就觉得兴奋。
你会选哪个?评论区投票告诉我👇
别追最强的模型,追最适合你场景的那个。
省下的钱和时间都是真的。
数据来源:LMSYS Chatbot Arena · 各模型官方API定价页 · SWE-bench Verified Leaderboard