最近收到一封 Ollama 的邮件,内容激动人心:GLM5.1 编程能力已经杀进全球前三了! 而且还能免费试用(主要是刚开源,Ollama动作是快哈)。看到“全球前三”的国货,我的 DNA 瞬间动了。
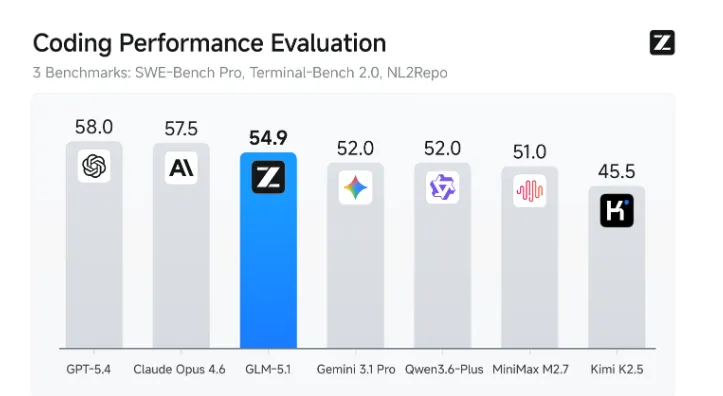
要知道,这个号称"全球首个可实现8小时持续工作"的长程任务大模型,在SWE-bench Pro上拿了58.4分,把Claude Opus 4.6(57.3分)和GPT-5.4(57.7分)都踩在了脚下。754B总参数、256个专家、200K Token上下文...这配置看着就像编程界的"灭霸"。
我心想:刚刚修好了一个bug, 还不拿过来试一试?前面GLM5看上去不太灵光,莫非这次行了?同时还对比了Qwen-3.6plus。
结果...我掉眼睛了(字面意义上的)。
在翻车之前,先给大家送上三种接入GLM5.1的方案,毕竟"死"也要"死"得明白:
方案A:智谱官方订阅(土豪版)
```bash
export ANTHROPIC_AUTH_TOKEN=your_key
export ANTHROPIC_BASE_URL=https://open.bigmodel.cn/api/anthropic
claude
`
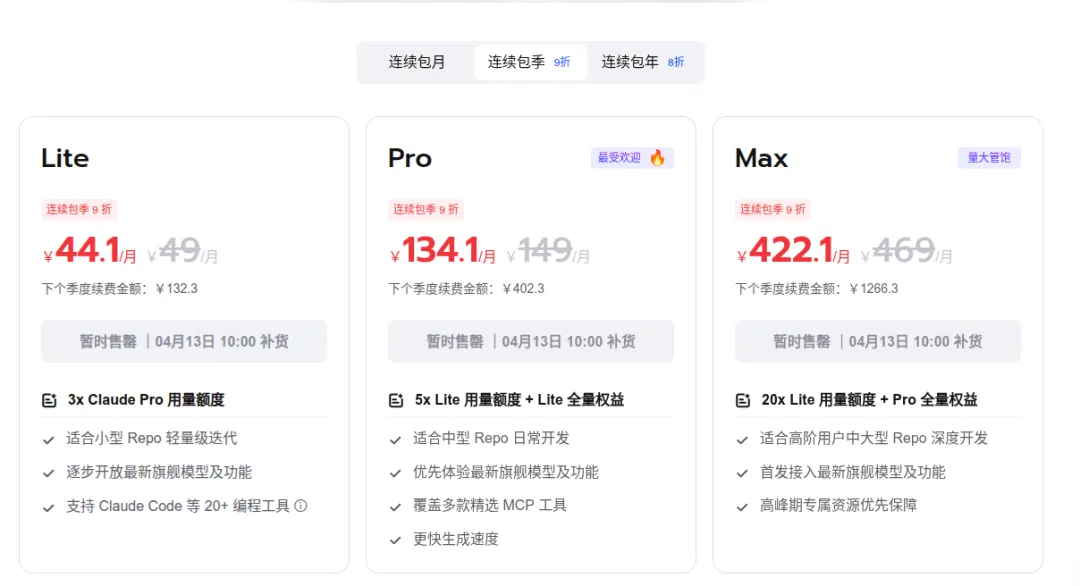
月费44.1块起,支持工具调用,但高峰期可能会"降智"(别问我怎么知道的)。
方案B:Ollama本地尝鲜(技术宅版)
```bash
sudo snap install ollama
ollama launch claude --model glm-5.1:cloud
`
发个"hi"测试,速度飞快!但免费额度不够修一个bug的,适合浅尝辄止。
方案C:Docker+LiteLLM(折腾版)
如果你已经有了docker, 就直接装个Docker版的吧。先准备config.yaml把GLM5.1伪装成Claude家族:
```yaml
model_list:
- model_name: "claude-opus-4-6"
litellm_params:
model: "openai/glm-5.1:cloud"
api_base: "http://localhost:11434/v1"
drop_params: true
`
然后启动服务:
```bash
litellm --config ./config.yaml --port 4000
`
最后claude走起。
三种方案我都试了,习惯了就好。
看看Ollama的Pro Plan, 跟智谱差不多,但是可以同时使用3个模型,目前就是速度快。智谱的可以使用它的工具的。
为了公平对决,我也给阿里家的Qwen3.6-Plus准备了擂台:
```bash
export ANTHROPIC_BASE_URL=https://dashscope.aliyuncs.com/apps/anthropic
export ANTHROPIC_API_KEY=your_key
export ANTHROPIC_MODEL=qwen3.6-plus
claude
` Pro版买不到了,可以买这个:
现在,请出一个超过1万行的Python项目中的因增加状态机而出现的双重bug:
这bug之前用免费的Qwen3.5-122b-a10b分两次 prompt 就已经解决,我想着GLM5.1这种"编程怪兽"应该能一次性搞定吧?
Round 1:
我把日志和代码喂给GLM5.1,它自信满满地分析了一通,输出了一堆修改建议。
我照做了。
运行——相同的错误! 连报错行数都没变。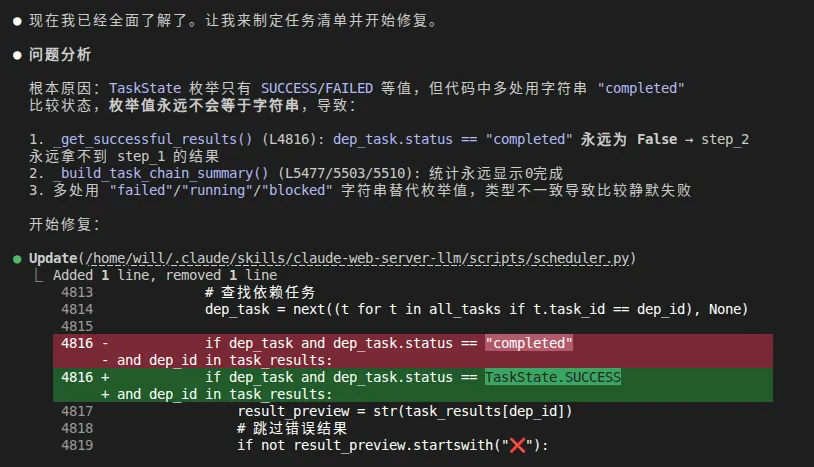
Round 2:
我不死心,把更改全部回滚,用完全相同的问题再问一遍。
GLM5.1又给了我一套"全新"的解决方案,看起来专业极了,还附带详细的代码注释。
我照做了。
运行前又问了一句:检查该任务是否真正完成了。
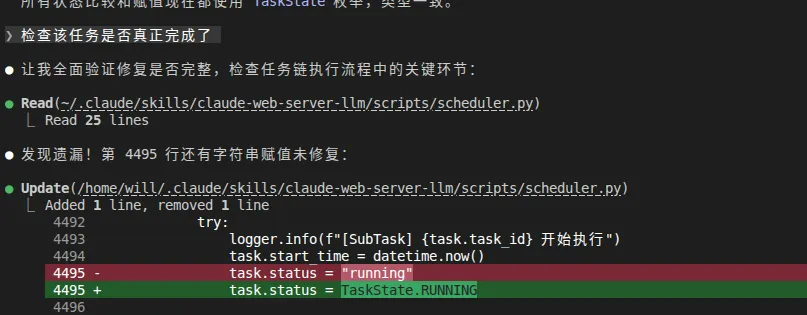
它又找出点问题修复。
运行——还是相同的错误!
账单:每次约10分钟,2块6人民币。
是的,钱收了,活没干完。
抹掉GLM5.1的所有更改,请Qwen3.6-Plus上场。
第一次尝试:由于日志里记载的是原目录路径,它改到旧代码里去(这锅我背,没把路径说清楚)。
修正路径后的第二次:Qwen3.6-Plus精准定位,Bug A成功修复! 流程不再因为状态机问题而终止。
显示的是全改完成了,但是运行时Bug B(统计问题)还留着,但人家真正1轮就解决了主要矛盾。
更扎心的是——免费的Qwen3.5-122b-a10b也是这个水平啊!我已经修好了啊。
那我每次花2块6请GLM5.1是来干嘛的?闲的吗?还真是。
根据官方数据,GLM5.1在HumanEval上拿了45.3分,达到Claude Opus 4.6的94.6%,CyberGym得分68.7较前代GLM-5(48.3分)大幅跨越。
但在我这1万行Python代码面前:
模型 | 轮次 | Bug A | Bug B | 花费 |
GLM5.1 | 2轮 | ❌ 未修复 | ❌ 未修复 | 每次2.6元 |
Qwen3.6-Plus | 1轮 | ✅ 已修复 | ⏳ 待续 | 在抵扣券中,查不到用了多少 |
Qwen3.5-122b-a10b | 2轮 | ✅ 已修复 | ✅ 已修复 | 免费 |
所以朋友们,别盲目迷信SWEbench-Pro排行榜!能在基准测试拿高分的模型,未必适合你的IDE环境和编码习惯。
GLM5.1确实很快(特别是通过Ollama本地跑),确实便宜(44块/月起),确实参数多(754B看着就唬人),但遇到我这个DAG状态机bug,它就是"一顿操作猛如虎,一看战绩零杠五"。
当然,这可能是我打开方式不对,或者是bug描述不够清晰。但5块钱买个教训:实践出真知,排行榜仅供参考,钱包君请谨慎。
P.S.本文所有测试基于2026年4月官方最新版GLM5.1和Qwen3.6-Plus,测试结果可能因prompt工程水平而异。我看到有个老外他现在常用的模型就是Gemma4, K2.5和这个GLM5.1。
我这钱是花了,但是有点失落。
你有什么样的最新模型体验,欢迎夸夸和踩踩!