为什么评测只差几分,真实体验却像差了一代?
在编程模型的讨论里,有个非常让人困惑的现象——很多榜单上,第一名和后面几名的差距往往只有 2% 到 5%。比如一个跑了 55 分,另一个 57 分,表面上似乎只是“稍微强一点”。
但只要你把这些模型真正放进持续性的开发任务里,体感就会迅速变得极其鲜明:这根本不是 80 分和 75 分的区别,而是一个基本能用,另一个基本不能用的断层差距。
为什么排行榜上的分差这么小,真实体验却差得这么夸张?最近这篇 SWE-CI 论文给出了一个相当有说服力的答案。
它把一个真实工程里极其关键、却常常被榜单忽略的问题正式提了出来:我们到底是在评估模型“会不会一次把代码改对”,还是在评估它“能不能在持续演化中把代码库维护好”?
这两件事,远不是一回事。
榜单测的是单次解题,工程考的是持续演进
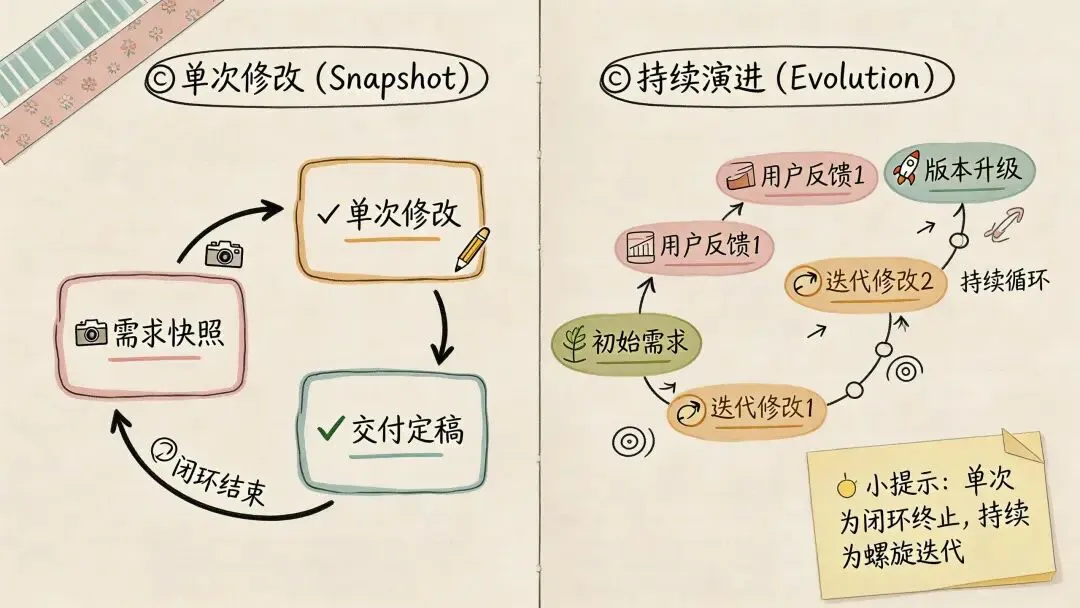
过去几年,大多数编程 benchmark 测的都是一次性快照(snapshot-based evaluation)。给你一段静态代码,给你一个任务描述,看你能不能写出正确的补丁让测试跑通。
这种方式能衡量模型理解代码和定位问题的能力。但它有一个致命局限——它只看这一次改得对不对,根本不管这次改动会不会把后面的演化路径带偏。
这就好比考试只看这道题是否答对,却不看你解题时埋下了多少隐患。你可以用极其脆弱、高耦合、毫无扩展性的方式把当前测试跑通。在静态榜单里,这种“打补丁”式的代码,和一个真正可维护的实现拿的是同样的分数。
于是,很多模型之间的真实能力差距被显著压缩了。
在真实软件工程里,代码是活的。前一轮代码并不会在任务结束后被“重置”。你今天做的粗糙抽象、局部权宜之计,都会原封不动地进入下一轮,继续推高后面的开发成本和回归风险。
真正重要的问题从来不是“这个模型这一次能不能改对”,而是“连续做很多轮修改之后,代码库是变得更容易维护了,还是越来越难以收拾”。
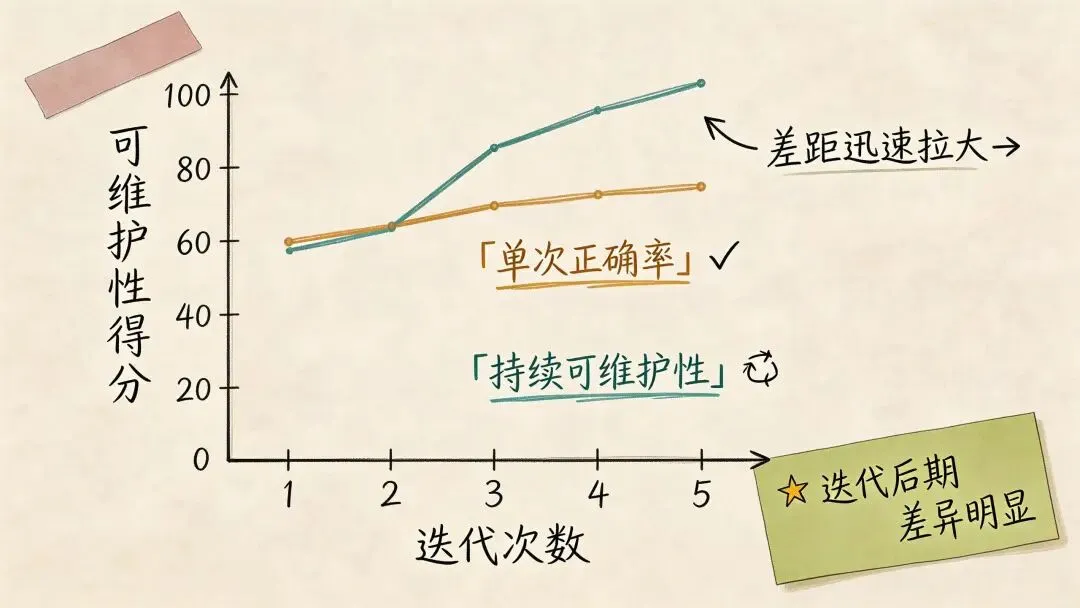
一旦把评测对象换成持续演化能力,模型间的差距就不再是几个百分点。因为在这种场景下,错误会累积,回归会传染,糟糕的设计决策会不断放大后续开发的摩擦成本。
零回归率:这才是区分模型的分水岭
如果把这个视角代入当前最强的编程模型,很多事情就说得通了。
Claude Opus 4.6 之所以在真实工程中的体感优势远大于榜单分差,并不是因为用户主观滤镜更强。而是因为传统的榜单更容易测出“单轮平均正确率”,却测不出“多轮迭代的稳定性”和“对回归的控制能力”。
单轮任务里,很多模型都能像模像样地交出答案。但在持续任务里,问题会迅速变成:第二轮还能不能接住第一轮留下的结构?第五轮会不会出现各种兼容性问题?第十轮之后,代码库是更清晰了,还是已经被补丁式修改搞得面目全非?
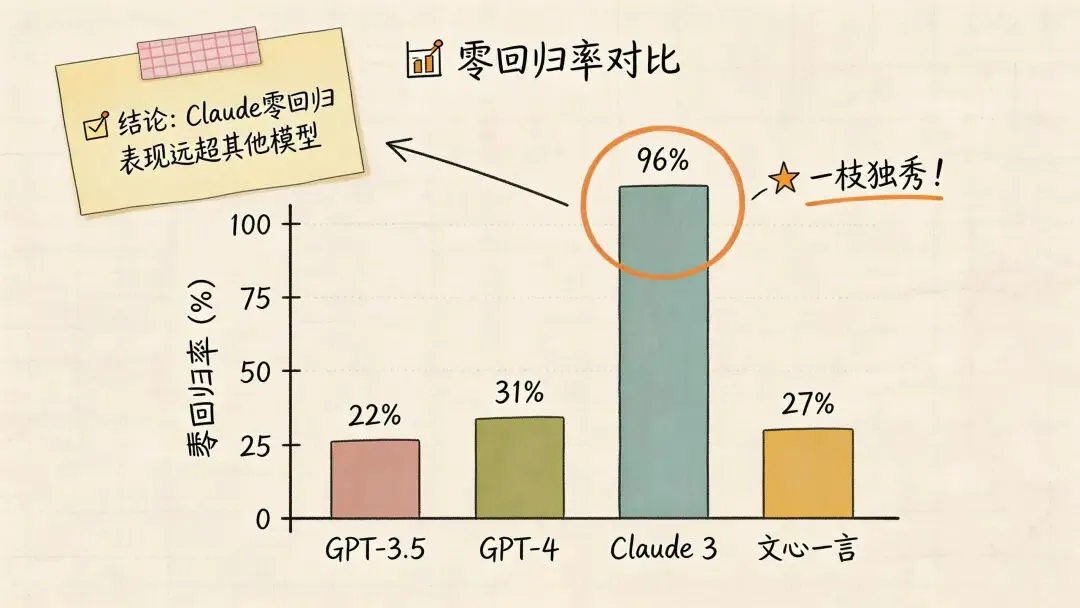
SWE-CI 这篇论文在评测中引入了一个非常有现实意义的指标——Zero-regression rate(零回归率)。也就是在整个长期维护过程中,从未引入回归错误的样本比例。
这测的不是偶尔高光时刻有多亮眼,而是你在持续维护中到底靠不靠谱。
结果很残酷,大多数模型在这项指标上表现都不高,而 Claude Opus 4.6 明显更强。这意味着它的优势不只是“平均多做对几道题”,而是更接近真实工程里最稀缺的能力——在持续演进中保持系统稳定,不轻易把已经跑通的逻辑打坏。
一旦落到真实工作流里,这绝不会只是榜单上的几个点。因为在真实团队协作中,最昂贵的从来不是“这轮任务没做完”,而是做完了却留下隐患、表面完成却破坏了已有逻辑。
这也是为什么很多工程师最终的体感是:第一名不是更聪明一点,而是终于开始具备了一定的工程可用性;而后面的模型虽然也会写代码,但离真正可用还差着一道深沟。
别把小任务的高分,当成大型工程的入场券
SWE-CI 其实在提醒整个行业:我们不能把模型在小任务上的亮眼表现,直接外推出它在大型真实工程中的长期维护能力。
小任务评测看的是功能能不能快速做出来、一次性交付是否成功。而企业级工程(尤其是大型 monorepo 和长生命周期系统)更关心的是,这次改动是否破坏了架构一致性?有没有给未来演进留下空间?系统整体是在变好还是劣化?
一个模型可以非常擅长 vibe coding,几分钟搭出一个惊艳的 demo(而这确实没啥损失,你可以试试)。但这并不意味着它能胜任大型工程里的长期架构演进。
在历史包袱之上继续演进,在复杂依赖里避免局部最优,在不断新增需求时保持代码库不劣化——这才是工程里真正困难的地方。
SWE-CI 并没有完全解决软件可维护性的评测难题,但它至少把“代码能不能长期活下去”这个核心问题,正式带进了大模型评测的视野。
真正决定模型工程价值的,未必是它能不能漂亮地完成某一次修改,而是它能不能在持续迭代中,不断把系统往更健康的方向推进。从这个标准看,SOTA 模型的重要性会被放大,而当前模型能力的边界也会被更加清晰地暴露出来。