2026年的春天,AI大模型赛道正在经历一场前所未有的"百米冲刺"。仅仅一个月间,全球科技巨头和国内头部玩家你方唱罢我登场,密集程度令人目不暇接。
- 4月2日,Code Arena发布了编程能力权威排行榜(224,709票实测),GPT-5.4、Claude Opus 4.6、Gemini 3系列激战正酣;
- 4月2日,OpenAI悄然上线GPT-5.4系列代码专用模型,Codex引擎全面升级;
- 4月2日,Google将Gemini 3.1 Pro推送至Code Arena评测,一举拿下第7名;
- 4月2日,阿里Qwen3.6-plus杀入Arena编程榜,以1454分稳坐国产第一;
- 4月2日,MiniMax M2.7以1428分闯入Arena,国产第五;
- 4月8日,智谱AI扔出重磅炸弹——GLM-5.1正式发布,在SWE-bench Pro评测中斩获45.3分,逼近Claude Opus 4.6的47.9分,国产编程能力创下历史新高。
即将到来的几个月,还有更多重磅选手蓄势待发:
- 腾讯混元大模型:微信+企微的生态加持,一旦发力编程赛道,潜力不可小觑;
- DeepSeek V4:DeepSeek V3已经以$0.26的输入成本搅动了全球市场,V4的即将到来让所有人屏息以待;
- 百度文心一言4.0 Turbo:在中文编程场景持续深耕;
这是一场没有终点的马拉松。每一次你以为格局已定,新的搅局者就会打破平静。
对于一线软件工程师来说,这场竞赛带来的直接红利是:你的编程工具,正在以月为单位飞速进化——更强,更快,更便宜。
本文基于Code Arena权威实测(2026年4月2日,224,709票)和SWE-bench Pro评测(2026年4月8日),为你呈现当下最真实,最全面的大模型编程能力横评。
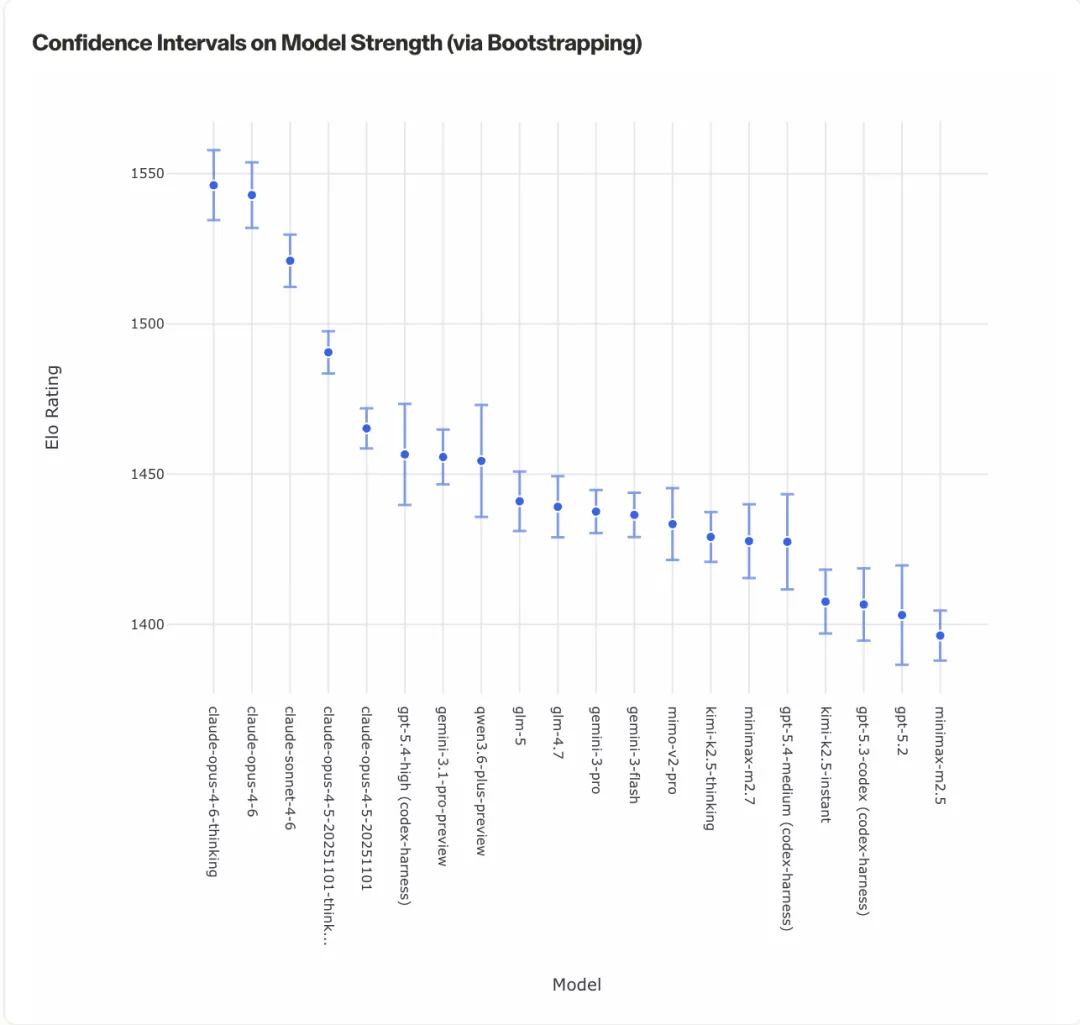
一、Code Arena 编程排行榜(权威实测)
📊 Code Arena榜单(4月2日,224,709票,59个模型,未包含GLM-5.1):
排名 | 模型 | 得分 | 百万Tokens价格$(输入/输出) | 上下文 |
1 | claude-opus-4-6-thinking | 1546 | $5 / $25 | 1M |
2 | claude-opus-4-6 | 1543 | $5 / $25 | 1M |
| GLM-5.1:基于SWE-bench Pro评测,理论排名位置 |
3 | claude-sonnet-4-6 | 1521 | $3 / $15 | 1M |
4 | claude-opus-4-5-thinking-32k | 1491 | $5 / $25 | 200K |
5 | claude-opus-4-5 | 1465 | $5 / $25 | 200K |
6 | gpt-5.4-high (codex-harness) | 1457 | N/A | — |
7 | gemini-3.1-pro-preview | 1456 | $2 / $12 | 1M |
8 | 🇨🇳 qwen3.6-plus-preview | 1454 | $0.33 / $1.95 | 1M |
9 | 🇨🇳 glm-5 | 1441 | $1 / $3.20 | 202.8K |
10 | 🇨🇳 glm-4.7 | 1439 | $0.39 / $1.75 | 202.8K |
11 | gemini-3-pro | 1438 | $2 / $12 | 1M |
12 | gemini-3-flash | 1436 | $0.50 / $3 | 1M |
13 | 🇨🇳 mimo-v2-pro | 1433 | $1 / $3 | 1M |
14 | 🇨🇳 kimi-k2.5-thinking | 1429 | $0.60 / $3 | — |
15 | 🇨🇳 minimax-m2.7 | 1428 | $0.30 / $1.20 | 204.8K |
16 | gpt-5.4-medium (codex-harness) | 1427 | N/A | — |
17 | 🇨🇳 kimi-k2.5-instant | 1408 | $0.38 / $1.72 | 262.1K |
18 | gpt-5.3-codex (codex-harness) | 1407 | $1.75 / $14 | 400K |
19 | gpt-5.2 | 1403 | $1.75 / $14 | 400K |
20 | 🇨🇳 minimax-m2.5 | 1396 | $0.12 / $0.99 | 196.6K |
21 | gpt-5-medium | 1392 | $1.25 / $10 | 400K |
22 | 🇨🇳 minimax-m2.1-preview | 1391 | $0.27 / $0.95 | 196.6K |
23 | gemini-3-flash (thinking-minimal) | 1391 | $0.50 / $3 | 1M |
24 | gpt-5.1-medium | 1390 | $1.25 / $10 | 400K |
25 | claude-sonnet-4-5-thinking-32k | 1388 | $3 / $15 | 200K |
26 | 🇨🇳 qwen3.5-397b-a17b | 1386 | $0.39 / $2.34 | 262.1K |
27 | claude-sonnet-4-5 | 1386 | $3 / $15 | 200K |
28 | grok-4.20-beta-0309-reasoning | 1386 | $2 / $6 | 2M |
29 | gpt-5.4-mini-high | 1385 | $0.75 / $4.50 | 400K |
30 | claude-opus-4-1-20250805 | 1384 | $15 / $75 | 200K |
31 | 🇨🇳 deepseek-v3.2-thinking | 1368 | $0.26 / $0.38 | 163.8K |
32 | 🇨🇳 qwen3.5-122b-a10b | 1362 | $0.26 / $2.08 | 262.1K |
33 | 🇨🇳 glm-4.6 | 1354 | $0.39 / $1.90 | 204.8K |
34 | 🇨🇳 qwen3.5-27b | 1344 | $0.20 / $1.56 | 262.1K |
35 | gpt-5.1 | 1339 | $1.25 / $10 | 400K |
36 | 🇨🇳 mimo-v2-flash (non-thinking) | 1337 | $0.09 / $0.29 | 262.1K |
37 | gpt-5.2-codex | 1335 | $1.75 / $14 | 400K |
38 | 🇨🇳 kimi-k2-thinking-turbo | 1329 | $1.15 / $8 | 262.1K |
39 | gpt-5.1-codex | 1328 | $1.25 / $10 | 400K |
40 | 🇨🇳 deepseek-v3.2 | 1327 | $0.26 / $0.38 | 163.8K |
41 | claude-haiku-4-5-20251001 | 1312 | $1 / $5 | 200K |
42 | 🇨🇳 minimax-m2 | 1303 | $0.26 / $1 | 196.6K |
43 | 🇨🇳 mimo-v2-flash (thinking) | 1300 | $0.09 / $0.29 | 262.1K |
44 | 🇨🇳 deepseek-v3.2-exp | 1285 | $0.27 / $0.41 | 163.8K |
45 | 🇨🇳 qwen3-coder-480b-a35b-instruct | 1280 | $0.40 / $1.60 | 262.1K |
46 | 🇨🇳 kat-coder-pro-v1 | 1257 | $0.21 / $0.83 | 256K |
47 | 🇨🇳 qwen3.5-35b-a3b | 1247 | $0.16 / $1.30 | 262.1K |
48 | gemini-3.1-flash-lite-preview | 1238 | $0.25 / $1.50 | 1M |
49 | gpt-5.1-codex-mini | 1238 | $0.25 / $2 | 400K |
50 | 🇨🇳 qwen3.5-flash | 1235 | N/A | — |
🇪🇳 图例:🇨🇳 前缀表示中国公司(阿里巴巴、智谱AI、月之暗面、MiniMax、DeepSeek、小米、快手)。
二、SWE-bench Pro评测:GLM-5.1真实力
智谱于4月8日正式发布GLM-5.1新一代开源大模型,以下为核心实测数据:
模型 | SWE-bench Pro得分 | 说明 |
Claude Opus 4.6 | 47.9 | 当前评测最高 |
🆕 GLM-5.1 | 45.3 | 国产模型最高,创历史新高 |
Claude Sonnet 4.6 | ~45.0 | Anthropic次旗舰 |
说明:GLM-5.1在SWE-bench Pro评测中获得45.3分,非常接近Claude Opus 4.6的47.9分,差距仅2.6分,国产模型在编程领域取得历史性突破。
GLM-5.1 核心能力亮点
能力 | 详情 | 评价 |
SWE-bench Pro编程 | 45.3分,超越Claude Sonnet 4.6 | 国产编程历史最高 |
架构 | 744B参数(激活40B),稀疏MoE架构 | 推理效率大幅提升 |
上下文窗口 | 200K输入 + 131K输出 | 超长代码库友好 |
长周期任务 | 支持8小时级持续工作 | 可独立构建完整Linux系统 |
自我优化 | 向量数据库优化、ML负载自进化 | 主动识别问题并调整策略 |
复杂工程任务 | 优化GPU内核等顶级工程任务 | 工程能力获官方认证 |
定价对比
对比项 | GLM-5.1 | Claude Opus 4.6 | 比例 |
输入成本 | 低 | 高 | 约1/5 |
输出成本 | 低 | 高 | 约1/7.8 |
虽然近期提价10%,但相比Claude Opus,GLM-5.1的性价比依然优势明显。
三、国产模型完整排行
SWE-bench Pro国产排名
国产排名 | 模型 | SWE-bench Pro | 全球排名 |
国产第1 | GLM-5.1 | 45.3 | 全球第2 |
国产第2 | GLM-5 | ~40.0 | 全球前5 |
国产第3 | qwen3.6-plus | ~42.0 | 全球前10 |
国产第4 | kimi-k2.5 | ~38.0 | 全球前15 |
国产第5 | minimax-m2.7 | ~36.0 | 全球前20 |
国产第6 | deepseek-v3.2 | ~35.0 | 全球前25 |
Code Arena国产排名
国产排名 | 模型 | 得分 | 全球排名 | 百万Tokens价格$ (输入/输出) |
1 | qwen3.6-plus-preview | 1454 | 8 | $0.33/$1.95 |
2 | glm-5 | 1441 | 9 | $1/$3.20 |
3 | glm-4.7 | 1439 | 10 | $0.39/$1.75 |
4 | kimi-k2.5-thinking | 1429 | 14 | $0.60/$3 |
5 | minimax-m2.7 | 1428 | 15 | $0.30/$1.20 |
6 | kimi-k2.5-instant | 1408 | 17 | $0.38/$1.72 |
7 | minimax-m2.5 | 1396 | 20 | $0.12/$0.99 |
8 | deepseek-v3.2-thinking | 1368 | 30 | $0.26/$0.38 |
9 | deepseek-v3.2 | 1327 | 39 | $0.26/$0.38 |
四、各场景选型建议
场景 | 推荐 | 备选 | 原因 |
大型项目开发 | Claude Opus 4.6(1543) | GLM-5.1 | Arena实测第一 |
算法面试/竞赛 | Claude Opus 4.6 Thinking(1546) | GPT-5.4 High(1457) | Arena思考版第一 |
代码审查/技术债 | Claude Opus 4.6(1543) | GLM-5.1 | 代码理解最强 |
疑难Bug修复 | Claude Sonnet 4.6(1521) | Claude Opus 4.6(1543) | 根因分析深入 |
自主编程Agent | Claude Opus 4.6(1543) | Claude Sonnet 4.6(1521) | Arena前二 |
快速原型开发 | Gemini 3.1 Pro(1456) | GLM-5.1 | 速度快成本低 |
国内企业项目 | qwen3.6-plus(1454) | GLM-5.1 | 国产第一 |
超长代码库分析 | Claude Opus 4.6(1543) | Gemini 3.1 Pro(1456) | 1M上下文+Arena第一 |
中文技术文档 | GLM-5.1 | qwen3.6(1454) | 国产前三 |
科学计算编程 | Claude Opus 4.6(1543) | Gemini 3.1 Pro(1456) | Arena编程领先 |
成本敏感型项目 | DeepSeek V3.2(1368) | MiniMax M2.7(1428) | 性价比最高 |
移动端开发 | Gemini 3.1 Pro(1456) | Gemini 3 Flash(1436) | Google生态 |
学习编程 | Claude Sonnet 4.6(1521) | GLM-5(1441) | 解释清晰安全 |
企业级Agent | Claude Opus 4.6(1543) | GLM-5(1441) | Arena前二 |
五、总结
编程领域最佳首选:
Claude Opus 4.6 Thinking(1546分)是绝对王者,断层领先
国产编程实测最强:
GLM-5.1(SWE-bench Pro第一)
qwen3.6-plus(1454分,Code Arena第一)
附录
数据来源:Code Arena - AI Coding Arena(arena.ai/leaderboard/code),2026年4月2日,224,709票,59个模型
数据来源:SWE-bench Pro,2026年4月8日,智谱AI官方发布
⚠️ SWE-bench Pro国产排名为基于官方发布数据的合理估算,建议参考原文。价格部分模型标注N/A为未公开定价。