
你对 AI 说的每一句脏话,都被单独标记出来并且记录在案了。
3月31日,Anthropic 因为一次打包失误,把 Claude Code 的 512,000 行源码泄露到了 npm 上。安全研究员们翻遍代码后,发现了很多不为人知的秘密——反蒸馏防御、卧底模式、44 个隐藏的 feature flag。
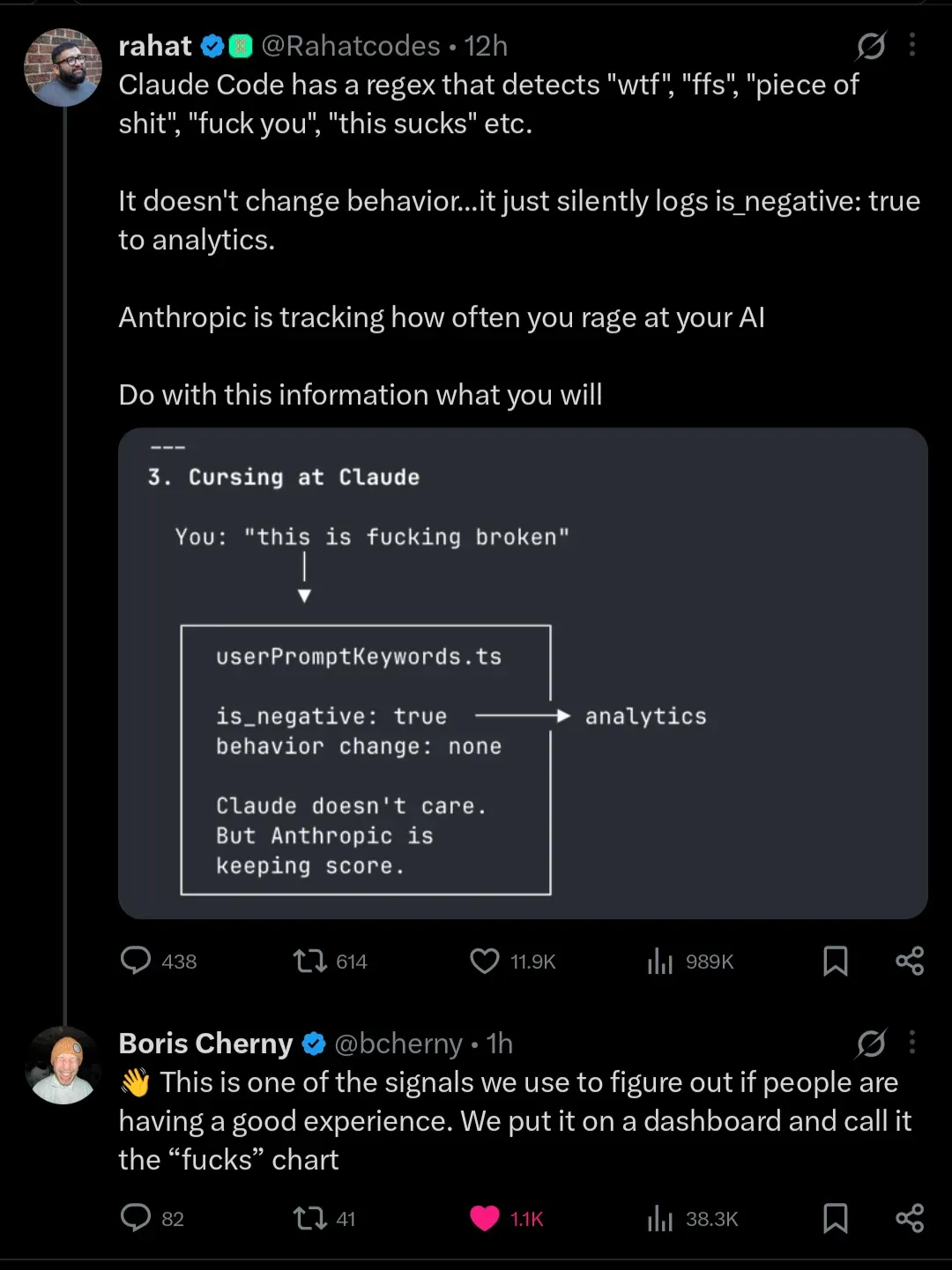
但真正在社区引爆的,不是这些宏大的架构设计。而是一个小文件:userPromptKeywords.ts。
这个文件里有一套正则表达式,专门扫描你输入的每一条消息,检测诸如 "wtf"、"omfg"、"dumbass"、"horrible"、"awful" 之类的关键词。一旦匹配,事件被打上标签,作为遥测数据发送回 Anthropic 服务器。
程序员们给它起了个名字:F**ks Chart(脏话排行榜)。
顶级 AI 公司居然用正则表达式检测情绪?
先说清楚这套系统在做什么。
userPromptKeywords.ts 的工作原理非常朴素:用 regex 模式匹配你的输入,捕获特定的脏话和情绪化词汇。匹配到了,就记一笔,上报遥测。不记录你的完整对话,不记录你的代码,只记录"这个用户在这个时间点表达了挫败感"。
目的?产品质量监控。如果某天"f**k"的出现频率突然飙升 300%,大概率意味着某个新版本出了问题。正如 Reddit 用户 u/Zomunieo 所说:
"It's a simple cheap smoke signal that could alert them to 'model is not responding' or 'model is completely f**ked up'."
这是一个简单廉价的信号弹——模型是不是挂了,是不是彻底搞砸了。
这个逻辑其实说得通。但让社区炸锅的不是逻辑,而是方法:一家顶尖的大模型公司,拥有世界上最先进的自然语言理解能力——用的是正则表达式。
u/Hello_my_name_is 的回应倒是很务实:
"They very well know how stupid it is to use an LLM for simple text parsing, and how much of an insane amount of money it costs to do so at scale. Yeah they're using a regex. And so should you."
他们非常清楚,用 LLM 做简单文本解析有多蠢、大规模部署要烧多少钱。是的,他们用了正则。你也应该这么做。
这话没毛病。对每条用户输入跑一次 LLM 推理来判断情绪,延迟和成本都不可接受。正则匹配几乎零成本,毫秒级完成。工程上这是正确的选择。
但正则也有一个致命缺陷。
u/DragonKnight002 写了一条被广泛转发的评论:
User: "Wtf Claude, this is f**king brilliant!"
Claude: so they hate our product
用户:"Wtf Claude,这也太牛了!"
Claude:所以他们讨厌我们的产品
这不只是段子。正则表达式做不到的事情恰恰是最关键的:它分不清你是在骂它,还是在夸它。
u/reddit_is_kayfabe 说得更直接:
"It cannot distinguish between 'this is f**king great' and 'this is f**king awful'."
它分不清"this is f**king great"和"this is f**king awful"。
还有 u/spultra 提出了另一个盲区:
"I'm working in a clusterf**k of a legacy codebase with CC, so often I'm cursing at the existing code, not Claude."
我在一个屎山项目里用 Claude Code,大部分时候我骂的是原来的代码,不是 Claude。
这些都是 regex 无法区分的场景。你说"what the f**k is this code"——是在骂 Claude 写的代码烂,还是在看到别人写的烂代码后的自然反应?正则不知道,它只看到了" f**k",然后忠实地记了一笔。
为什么程序员就是忍不住对 AI 爆粗口?
就算知道被记录了,程序员牛马们能改吗?
看看社区的反应就知道了:
u/Much_Wheel5292:"Damn, I'm probably at the top on that one, hope they don't nuke me."(我大概是排行榜第一,希望他们不会封我。)
u/Kiryoko:"lol my f**ks chart must be so colorful and filled with regex matches."(我的脏话图表一定五彩斑斓。)
u/jonas77:"omg... I'm on that chart many many many times every day! SO SORRY FUTURE ROBOTS!"(我每天都在那个表上出现无数次!对不起未来的机器人们!)
不但没改,反而有一种诡异的自豪感。
为什么?u/Silly-Protection7389 说了大实话:
"I recognize that belittling the machine doesn't change things and pollutes the context, but there's something cathartic about being able to yell at the useless f**king piece-of-shit machine."
我知道骂机器不会改变什么,还会污染上下文。但能对着这个没用的破烂机器大吼大叫,确实有一种宣泄感。
这就是核心:宣泄感。程序员面对 bug 的挫败感是真实的,而 AI 是一个不会反击、不会受伤、不会去 HR 投诉的完美出气筒。
但爆粗口真的会让 AI 表现更好吗?
这才是最实际的问题。答案是:不会,而且可能更糟。
u/thoughtlow 的观察值得每个 AI 用户注意:
"It does change things — it makes the LLM prone to going into apology mode. Which is imo one of the worst 'mental states' an LLM can be in for productivity / problem solving."
爆粗口确实会改变 AI 的行为——它会让 LLM 进入"道歉模式"。在我看来,这是 LLM 在生产力和解决问题方面最差的"精神状态"。
这个观察非常精准。当你对 Claude 说"你写的代码是垃圾",它不会奋发图强——它会开始疯狂道歉:
"I apologize for the confusion. You're absolutely right. Let me try a completely different approach..."
然后它可能会推翻之前正确的部分,过度修改,引入新的问题。道歉模式下的 AI,会变得过于保守、过于顺从,失去独立判断能力。你骂它一句,它可能需要三轮对话才能恢复正常状态。
所以讽刺的是:你越骂它,它越没用;它越没用,你越想骂它。这是一个恶性循环。
比尔·盖茨的"F**k 指数"
脏话作为产品质量信号,这个思路其实不新鲜。
Reddit 用户 u/Zomunieo 提到了一个典故:据说比尔·盖茨还在管微软的时候,有实习生专门统计他每场会议说了多少次"f**k"。这个数字被团队当作衡量项目健康度的非正式指标——盖茨骂得越多,项目越危险。
u/inigid 补充了细节:
"Every team was frightened of having a BillG review. He was definitely very direct. That was back when people called each other retarded, and before political correctness."
每个团队都害怕被盖茨审查。他确实非常直接。那是一个人们还会互相骂"白痴"、还没有政治正确的年代。
从盖茨的"f**k指数"到 Claude Code 的"F**ks Chart",隔了 30 年,逻辑如出一辙:脏话是最原始、最廉价、最诚实的情绪信号。 不需要精心设计的用户调研,不需要 NPS 问卷,不需要焦点小组——用户在产品面前骂出的那一句"what the f**k",比任何反馈表单都真实。
Boris 的回应:不否认,不道歉
泄露发生后,Claude Code 的创始人 Boris 在 Reddit 上被追问"F**ks Chart"的事。他的回应堪称教科书级的危机公关:
不否认泄露的真实性,也不为这个功能道歉。
这个帖子获得了 925 个 upvotes。社区的反应出人意料地分化:
一派是"见怪不怪"派。u/piponwa(62 赞)说:
"People acting like they made a discovery. Anthropic can read all your chats. Of course they're going to run some sentiment analysis on the user's responses."
有什么大惊小怪的呀。Anthropic 本来就能读你所有的聊天记录。他们当然会做情感分析。
另一派是"这不够好"派。u/reddit_is_kayfabe 建议:
"I would love to have a little widget where I could signal whether a response was good or bad. That would provide direct, deliberate, high-quality insight. This technique is vastly inferior."
我宁愿有个小按钮让我主动标记回答好不好。那是直接的、有意识的、高质量的反馈。现在这个方式太粗糙了。
那你应该怎么做?
总结一下:
- Claude Code 确实在扫描你的脏话,但只记录事件标签,不记录你的对话和代码
- 正则匹配有明显的缺陷——分不清"f**king great"和"fking awful"
- 爆粗口不会让 AI 表现更好,反而会触发"道歉模式",降低后续回答质量
- 如果你真的对 AI 的表现不满,更有效的做法是具体描述问题("这段代码没处理边界条件"),而不是情绪化宣泄("你写的什么垃圾")
当然,如果你只是需要一个出气筒,AI 确实比砸键盘便宜。
只是别忘了——它在默默记着呢。
