仅2B参数登顶HF Open ASR排行榜第一——Cohere首次杀入语音就拿下榜首
- 更新时间 2026-03-30 11:59:56

关注下方“公众号”,获取更多开源资讯
导读
语音识别领域的竞争格局正在快速变化。过去一年,IBM Granite、NVIDIA Canary、Qwen3-ASR、ElevenLabs Scribe先后刷新HuggingFace Open ASR(Automatic Speech Recognition,自动语音识别) Leaderboard成绩,模型参数从1B到4B不等,技术路线也出现分化——部分团队将ASR构建在预训练大语言模型之上,另一部分坚持专用编码器-解码器架构。
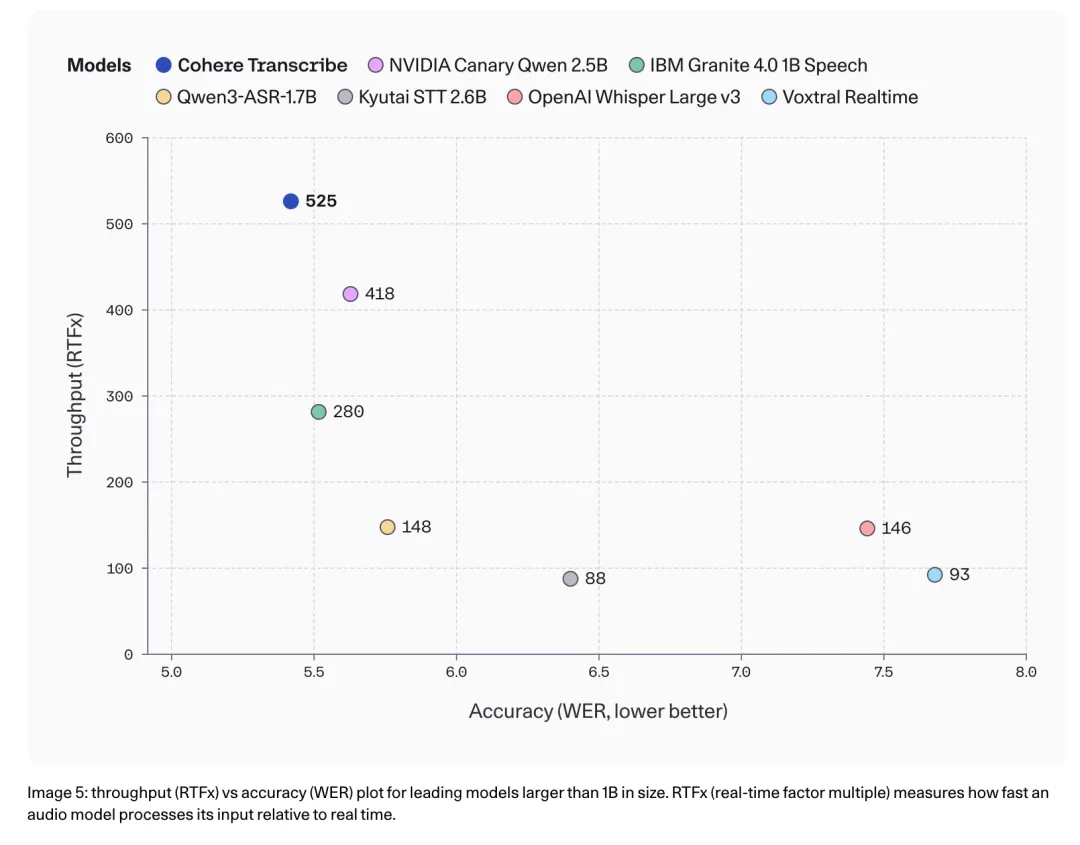
2026年3月26日,一个此前从未涉足音频领域的玩家——Cohere Labs发布了其首个语音模型cohere-transcribe-03-2026,以2B参数、平均WER 5.42%登顶Open ASR Leaderboard英语榜首,比OpenAI Whisper Large v3的7.44%相对改进约27%。与此同时,该模型的推理吞吐量达到RTFx 525(每分钟处理525分钟音频),在精度和速度两个维度同时取得领先。模型以Apache 2.0许可证开源,支持本地部署。
本文将从排行榜数据、架构设计、多语言能力、部署方式四个维度展开介绍。
项目信息
一、Open ASR Leaderboard:2B如何登顶排行榜?
HuggingFace的Open ASR Leaderboard是当前ASR模型最主要的公开评测平台之一,覆盖8个英语测试子集,涵盖会议录音(AMI)、财报电话会议(Earnings22)、播客/广播(Gigaspeech)、朗读语音(LibriSpeech)、金融对话(SPGISpeech)、TED演讲(Tedlium)和欧洲议会(Voxpopuli)等多种场景。评测指标为WER(Word Error Rate,词错误率),越低越好。
以下是截至2026年3月26日的排行榜前列数据:
| Cohere Transcribe | 2B | 5.42 | 8.15 | 1.25 | 2.37 | |||||
| 1.59 | 5.37 | |||||||||
| 8.48 | ||||||||||
| 8.74 | 2.28 | |||||||||
数据来源:HuggingFace模型页。表中加粗为该列最优值。
几个值得关注的点:
Cohere Transcribe在三个子集上取得全场最低WER:LibriSpeech clean(1.25%)、LibriSpeech other(2.37%)、AMI(8.15%)。LibriSpeech是ASR领域最经典的测试集,clean/other两个子集分别代表干净语音和含噪语音场景;AMI是多人会议录音,语音质量和说话风格都更贴近实际应用。
没有任何一个模型在所有子集上占优。Zoom Scribe v1在SPGISpeech(金融对话)和Voxpopuli上表现更好,IBM Granite在Earnings22上领先,Qwen3-ASR在Gigaspeech和Tedlium上更优。Cohere Transcribe的优势在于均衡性——它没有明显短板,平均WER 5.42%排名第一,较Whisper Large v3的7.44%相对改进约27%。
推理速度方面,据The Decoder报道,Cohere Transcribe的RTFx达到525,即每分钟可处理525分钟音频。作为对比,排名第二的NVIDIA Canary Qwen 2.5B为418。Cohere官方的描述是"比同等规模专用ASR模型快3倍"。这一速度优势来自其架构设计——下一节会具体展开。
图片来源于Hugging Face Cohere 原博客
二、不走LLM路线:专用编码器-解码器的设计哲学
当前ASR模型的技术路线出现了分化。一类方案将ASR构建在预训练大语言模型之上,例如Qwen3-ASR基于Qwen文本模型、IBM Granite 4.0 1B Speech基于Granite文本模型——它们利用LLM已有的语言理解能力,但自回归解码的计算开销较大。另一类方案则沿用传统的编码器-解码器架构,为语音任务做专门设计。
Cohere Transcribe选择了后者。具体来说:
编码器:采用Fast-Conformer架构,这是一种结合卷积和自注意力的高效语音编码器。模型总共2B参数,90%以上的参数集中在编码器,负责将音频波形转化为高质量的声学表示。 解码器:使用轻量级Transformer解码器,仅占约10%的参数。由于解码器承担的自回归计算量较小,推理速度显著提升。 训练方式:整个模型从头训练(trained from scratch),不依赖任何预训练文本LLM。 分词器:16k多语言BPE(Byte Pair Encoding)分词器,带byte fallback机制,支持14种语言。 输入处理:音频采样率16kHz(自动重采样),多声道输入取平均为单声道,长音频默认按35秒分块处理。
这种非对称设计的核心思路是:把计算量集中在编码阶段(可以并行处理),最小化解码阶段的自回归计算。对于ASR任务而言,编码器负责"听懂"音频,解码器只需将声学表示转换为文本——这个过程不需要像通用LLM那样进行复杂的推理,因此轻量解码器就够用了。
在训练数据方面,Cohere团队使用了约50万小时的精选音频-文本对数据。团队提到,大部分模型开发周期投入在数据工作上,包括专有过滤管道、数据混合平衡、音频去污染检查(防止测试集与训练集重叠),以及SNR(Signal-to-Noise Ratio,信噪比)范围0-30 dB的噪声增强。
三、14种语言支持:强在哪里,弱在哪里?
Cohere Transcribe支持14种语言:
在多语言ASR排行榜上,Cohere Transcribe排名第4(开源模型中第2)。多语言评测使用FLEURS、Common Voice 17.0、MLS、Wenet等数据集,中文/日文/韩文使用CER(字符错误率),其他语言使用WER。
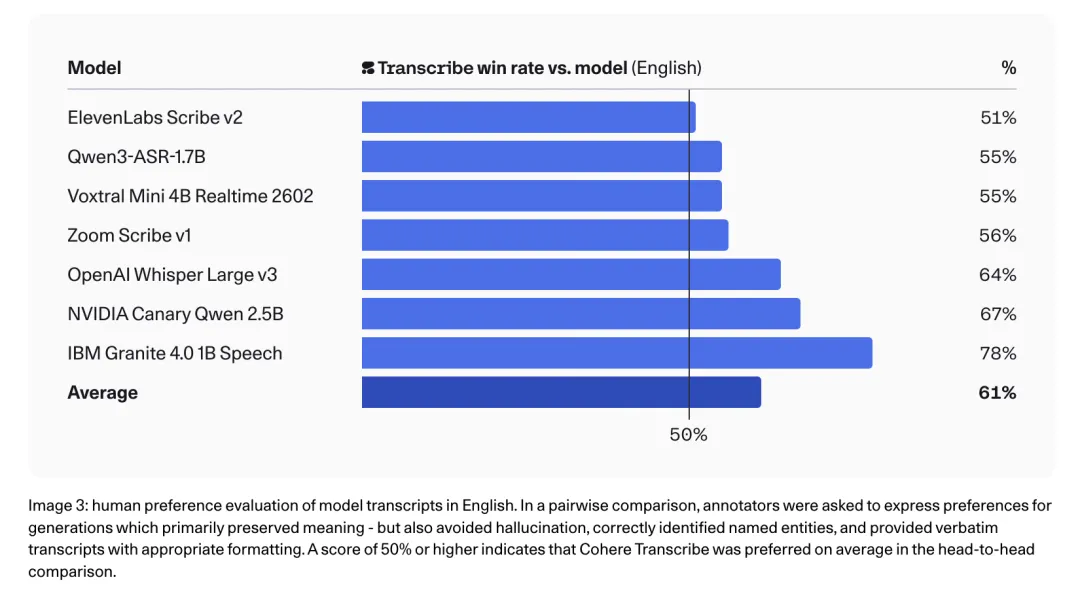
但排行榜WER只是一个维度。Cohere还做了人工评估(head-to-head对比),评估维度包括意义保持、幻觉避免、命名实体识别、逐字格式化与标点。先看英语结果:
| 55% | |
英语人工评估的平均胜率为61%,对所有竞品均达到50%以上。
图片来源于Hugging Face Cohere 原博客
多语言人工评估的情况则更复杂:
可以看到,在日语和意大利语上Cohere Transcribe表现较强,但在德语、葡萄牙语、西班牙语三种语言上胜率低于50%,意味着在这些语言上落后于竞品。这是一个需要注意的局限。
其他已知局限
除多语言弱项外,当前版本还有以下限制:
无时间戳:不提供字级或段级时间戳信息 无说话人分离:不提供说话人识别/分离功能 无自动语言检测:使用时必须预先指定语言代码 静音处理:对非语音声音倾向于生成转录文本,建议前置噪声门或VAD(Voice Activity Detection,语音活动检测)模型 语言混用:对code-switching(多语言混用)音频表现不一致
四、从API到本地部署:三种上手方式
Cohere提供三种使用方式:
| 免费API | |
| Model Vault | |
| 本地部署 |
生态集成方面,模型已支持transformers(>= 5.4.0原生支持)、vLLM(PR #38120已合并)、mlx-audio(Apple Silicon)、transformers.js + WebGPU(浏览器端)等框架。
以下是两个来自HuggingFace模型页的代码示例。
示例1:快速开始
from transformers import AutoProcessor, CohereAsrForConditionalGenerationfrom transformers.audio_utils import load_audiofrom huggingface_hub import hf_hub_downloadprocessor = AutoProcessor.from_pretrained("CohereLabs/cohere-transcribe-03-2026")model = CohereAsrForConditionalGeneration.from_pretrained("CohereLabs/cohere-transcribe-03-2026", device_map="auto")audio_file = hf_hub_download( repo_id="CohereLabs/cohere-transcribe-03-2026", filename="demo/voxpopuli_test_en_demo.wav",)audio = load_audio(audio_file, sampling_rate=16000)inputs = processor(audio, sampling_rate=16000, return_tensors="pt", language="en")inputs.to(model.device, dtype=model.dtype)outputs = model.generate(**inputs, max_new_tokens=256)text = processor.decode(outputs, skip_special_tokens=True)print(text)几行代码即可完成加载和转录。需要注意language="en"参数——模型不支持自动语言检测,必须显式指定语言代码。
示例2:长音频转录(55分钟财报电话会议)
from transformers import AutoProcessor, CohereAsrForConditionalGenerationfrom datasets import load_datasetimport timeprocessor = AutoProcessor.from_pretrained("CohereLabs/cohere-transcribe-03-2026")model = CohereAsrForConditionalGeneration.from_pretrained("CohereLabs/cohere-transcribe-03-2026", device_map="auto")ds = load_dataset("distil-whisper/earnings22", "full", split="test", streaming=True)sample = next(iter(ds))audio_array = sample["audio"]["array"]sr = sample["audio"]["sampling_rate"]duration_s = len(audio_array) / srprint(f"Audio duration: {duration_s / 60:.1f} minutes")inputs = processor(audio=audio_array, sampling_rate=sr, return_tensors="pt", language="en")audio_chunk_index = inputs.get("audio_chunk_index")inputs.to(model.device, dtype=model.dtype)start = time.time()outputs = model.generate(**inputs, max_new_tokens=256)text = processor.decode(outputs, skip_special_tokens=True, audio_chunk_index=audio_chunk_index, language="en")[0]elapsed = time.time() - startrtfx = duration_s / elapsedprint(f"Transcribed in {elapsed:.1f}s — RTFx: {rtfx:.1f}")print(f"Transcription ({len(text.split())} words):")print(text[:500] + "...")这个示例展示了长音频处理能力。模型内部按35秒分块处理,通过audio_chunk_index追踪分块信息,用户无需手动切割音频。示例同时计算了RTFx,方便评估实际吞吐表现。
vLLM部署
对于需要高并发服务的生产场景,模型已集成vLLM。Cohere团队为此向vLLM提交了PR #38120(已于2026年3月25日合并),包含三项改进:
细粒度并发编码器执行:重新设计调度器,支持并发编码器请求和可变序列长度,提升GPU利用率 可变长度音频原生支持:更新注意力元数据、KV-cache管理和模型接口,支持非均匀序列 紧凑张量表示:卷积编码器使用最小填充批处理,输出转为紧凑表示用于基于FlashAttention的解码器
这些改进解决了原vLLM将编码器输入填充到固定长度的瓶颈,在并发ASR工作负载下带来最高2倍的吞吐改善。
启动vLLM服务:
vllm serve CohereLabs/cohere-transcribe-03-2026 --trust-remote-code五、总结与思考
Cohere Transcribe作为Cohere Labs的首个音频模型,在几个方面值得关注:
精度-速度平衡:2B参数达到Open ASR Leaderboard英语榜首(WER 5.42%),RTFx 525的推理速度在同等精度的模型中领先。这种平衡来自非对称编码器-解码器设计——重编码器、轻解码器。 不依赖预训练LLM:与Qwen3-ASR、IBM Granite等基于LLM的方案不同,Cohere Transcribe从头训练专用架构。这条路线在当前LLM主导的趋势中是少数派,但结果表明专用架构在ASR任务上仍有竞争力。 开源且生态友好:Apache 2.0许可证,原生支持transformers和vLLM,降低了集成门槛。 多语言能力有长有短:英语和日语表现强势,但德语、葡萄牙语、西班牙语弱于竞品。缺少时间戳、说话人分离和自动语言检测,在需要这些功能的场景中仍需配合其他工具使用。
对于需要高精度英语转录、或需要本地部署ASR能力的开发者,Cohere Transcribe是一个值得评估的选项。对于多语言场景,建议先针对目标语言进行测试,尤其是德语、西班牙语和葡萄牙语。
Coovally AI Hub 解读AI前沿——顶会论文解读、开源项目精选、企业落地案例,帮你技术进阶与商业破圈。如果您有技术交流或合作意向,欢迎联系我们和评论区留言讨论~
© THE END
转载请联系本公众号获得授权

 分享、点赞与在看,至少帮我拥有一个~
分享、点赞与在看,至少帮我拥有一个~
