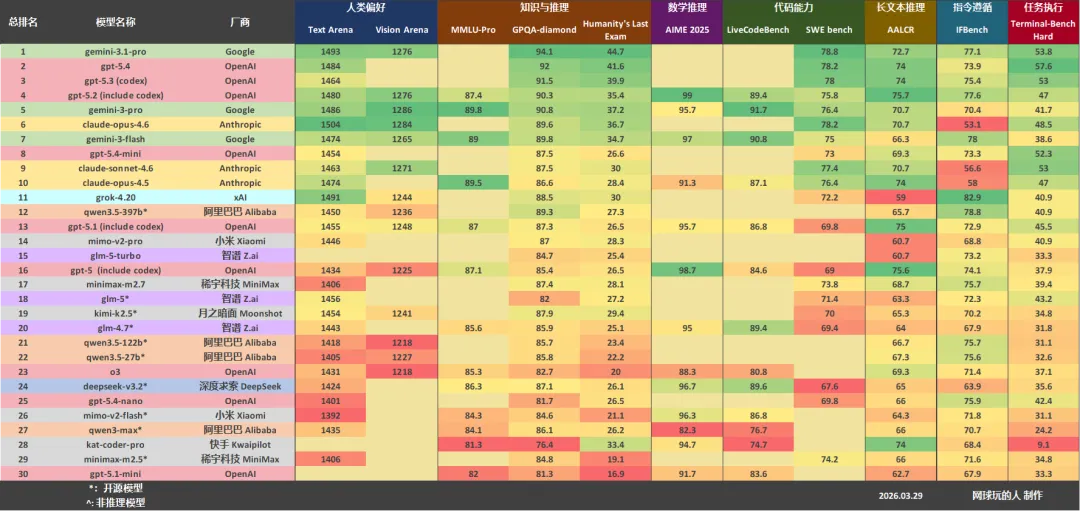
本周排名前10的模型为:
Gemini 3.1 Pro
GPT-5.4
GPT-5.3 (codex)
GPT-5.2
Gemini 3 Pro
Claude Opus 4.6
Gemini 3 Flash
GPT-5.4-mini
Claude Sonnet 4.6
Claude Opus 4.5
简介:
本表格汇总了常用大语言模型在主流评测排行榜上的表现。评测范围涵盖:
人类偏好(文字和视觉),知识与推理,数学能力,代码能力,长文本推理,和指令遵循能力等等
在整合各项评测结果的基础上,计算出综合排名。
更新:
顶端的几个大模型的水平相似,难分高下,本周Gemini 3.1 Pro暂回榜首。
本周新上榜了小米的MiMo-V2-Pro、智谱的GLM-5-Trubo,和MiniMax的miniMax-M2.7,都是闭源模型,且表现不错,排在表格中游。
因为MMLU-Pro、AIME2025、LiveCodeBench等榜单已经基本饱和,且Artificial Analysis网站不再更新新模型的数据,本表格也考虑引入新评测榜单,以替换这些榜单。
总结:
综合实力最强:Gemini 3.1 Pro/GPT-5.4
国内最强模型:Qwen 3.5 397b
最强开源模型:Qwen 3.5 397b
最强代码模型:Gemini 3.1 Pro/Claude Opus 4.6
本项目仓库:
https://github.com/Tennisatw/LLM-Leaderboard
如果觉得本图有帮助,欢迎点个⭐。