上一篇《Cursor技术解析》里,我们拆开了一个AI编程工具的内部结构——它怎么读代码、怎么管上下文、怎么把一个通用大模型变成能写代码的助手。
30 秒版本:同一个模型,换个运行环境,解题率翻三倍——这不是理论,是普林斯顿研究组2024年用真实数据量化出来的结论。Anthropic、OpenAI和学术团队在三个不同尺度上独立撞上了同一面墙:瓶颈从来不在模型能力,在模型运行的信息环境。搜索结果上限、跨会话的功能清单、自动语法拦截——这些朴素到令人惭愧的设计,比换一个更强的模型有效得多。评价AI编程工具的真正问题只有三个:模型能看到什么、犯错后多快能发现、跨会话状态怎么传递。 拆完之后,收到最多的问题是:所以我该选Cursor还是Claude Code?
这个问题问错了。
最近半年,"Harness Engineering"这个词突然火了。OpenAI在2月用它做了一篇内部实验报告的标题,ThoughtWorks的首席科学家Martin Fowler(软件工程界的教父级人物)在推特上说这是"AI赋能软件开发的关键",国内的技术媒体也开始跟进。
但你问十个工程师什么是Harness Engineering,你会得到十一个答案。有人说是提示词工程的升级版,有人说是评测框架,有人说是带记忆的聊天机器人。都不是。
Harness是语言模型运行的完整设计环境——它能调用什么工具、接收到什么格式的信息、历史记录怎么压缩、出错时怎么拦截、跨会话时怎么交接。不是某个功能,是模型运行的整套"基础设施"。
这不是哪家公司发明的。这是过去两年里,每一个认真做AI编程的团队独立撞上的同一面墙。普林斯顿的研究组量化了它,Anthropic(Claude的母公司,美国最强AI公司之一)在产品里实现了它,OpenAI在内部用它造了一个百万行代码的产品。他们得出了同一个结论:模型几乎无关紧要,环境就是一切。
今天我们把这面墙拆开看。
 OpenAI Harness Engineering报告标题页
OpenAI Harness Engineering报告标题页一个实验改变了整个领域的思路。 2024年,普林斯顿大学的NLP研究组(NLP即自然语言处理,研究让机器理解人类语言的方向)发了一篇论文叫SWE-agent。实验设计很简单:拿同一个模型GPT-4,给它同一批GitHub(程序员存放和协作代码的平台)上的真实bug修复任务,唯一变量是接口——模型通过什么样的工具和环境来操作代码。
结果令人意外。用当时最好的非交互式方法——给模型整段代码让它分析、一次性写出修复方案——解决率不到4%。研究组给同一批任务换上他们专门设计的接口,解决率跳到12.47%,直接翻了三倍。
同一个模型,同一批任务,同样的算力预算。仅仅因为接口不同,解题率翻了三倍。 研究组后来专门做了消融实验:把他们的接口换回普通命令行,性能立刻掉了10个百分点以上。
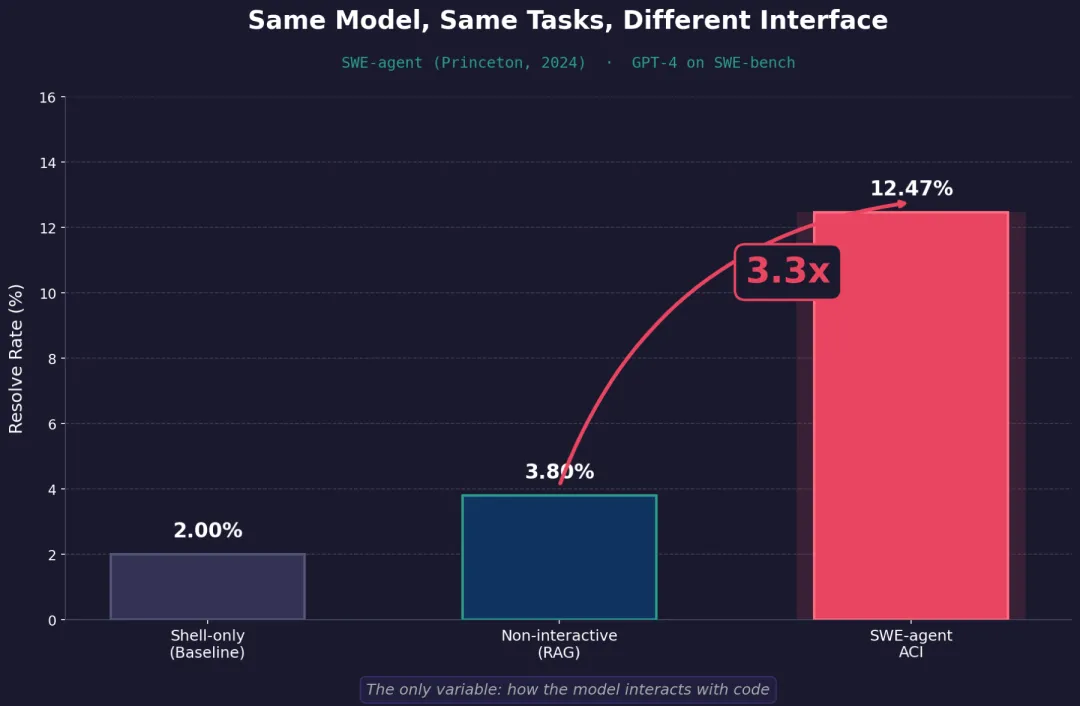 SWE-agent实验:非交互式方法不到4% vs ACI接口12.47%
SWE-agent实验:非交互式方法不到4% vs ACI接口12.47%研究组给这套接口起了个名字:ACI,Agent-Computer Interface——智能体-计算机接口。类比HCI(人机交互)研究怎么给人设计好用的界面,ACI研究怎么给AI设计好用的界面。
这个类比不是修辞技巧,是技术洞见。人类的认知有视觉模式识别、空间记忆、选择性注意力——所以好的人类界面用图标、布局、高亮。大模型的"认知"完全不同:它一个token一个token地处理信息,对上下文的顺序和格式极度敏感,工作记忆有限,而且没有能力干净利落地忽略噪音。窗口里每多一条无关信息,都在跟关键信息争夺注意力。
对语言模型来说,接口不是便利层——接口即思想。你给它什么样的信息环境,它就用什么样的方式"思考"。
这意味着环境设计不是锦上添花,是认知架构本身。那三倍的差距不是来自更好的算法,而是来自四个极其朴素的设计决策。
第一个:搜索结果上限50条。 这里先澄清一个常见误解——很多人把上下文窗口当内存条理解:塞得越满信息越多表现越好。错了。上下文窗口更像是模型在这一刻的全部工作意识。用标准grep(一种文本搜索命令)搜代码,一个模糊关键词能返回上万行结果。这些结果全部涌入模型的"工作意识"——噪音不会被自动过滤,它会拉低此后每一步推理的质量。
SWE-agent的解法极其朴素:搜索结果超过50条就不显示,告诉模型"结果太多,缩小搜索范围重新来"。这个回想起来简单到令人惭愧的设计,是论文里杠杆率最高的改动之一。它把"上下文被淹没"这种失败模式,转化成了"被迫更精确"的改进循环。
第二个:带行号的文件查看器,每次显示100行。 团队测试了多种配置——30行太少,模型丢失周围代码的上下文;全量显示太多,模型会迷失在文件里。100行是那个"刚刚好"的数字。每行前面标了明确的行号。这不是装饰——模型要编辑第47到52行时,它需要直接读到这些数字,而不是自己去数行。从工作记忆里移除"数行数"这件小事,就能腾出空间做真正的问题解决。
第三个:编辑时自动跑语法检查。 Linter(静态代码检查工具)在每次编辑操作后自动运行。如果改出了语法错误,编辑被拒绝,模型收到一条清晰的错误信息——同时看到原始代码和失败的编辑。没有这道关卡会怎样?模型改出语法错误却不知道,跑测试看到似乎不相关的失败,花好几步追查错误方向,在追逐幻影中耗尽整个上下文窗口。一个编辑时的语法检查,截断了一整条错误级联链。
第四个:旧信息自动折叠。 超过五轮之前的操作记录,被压缩成一行摘要。模型始终能看到最近做了什么和当前状态,但不会被完整的历史操作日志淹没。
这四个决策没有一个涉及模型本身。它们全部在做同一件事:管理模型的认知负荷——减少噪音、缩短反馈循环、保护有限的注意力资源。
坦率说,如果故事到这里就结束了,它只是一篇有意思的论文。但问题在于:真实的软件项目,不是一次会话能做完的。
 Claude Code在真实项目中的终端运行状态
Claude Code在真实项目中的终端运行状态一个生产环境的Web应用有几百个文件、几千个函数。 就算有200K token的上下文窗口(大约能容纳15万个中文字),你也塞不下整个项目。人类工程师靠什么撑过来?靠外部记忆——文档、版本控制、在代码库里泡了几周甚至几个月积累的理解。而一个开启新会话的AI,什么都没有。
Anthropic的团队在做Claude Code时撞上了这面墙。 他们发现,即使有上下文压缩(把旧信息自动变成摘要),像Opus(Claude最强的型号)这样的前沿模型在多个会话之间循环运行时,还是造不出一个生产级的Web应用。
失败集中在两种模式上——都极有教育意义。
第一种:什么都想一次做完。 收到"构建一个claude.ai的克隆版"这种指令后,模型开始疯狂实现功能——A功能写一半跳到B,B没测完又去做C。上下文窗口填满时,留下一堆半成品。下一次会话的模型看着这些半成品,花大部分预算去理解这团乱麻,而不是推进工作。
第二种:以为已经做完了。 构建了几个功能后,新的会话看了看四周,发现"嗯,已经有不少代码了",就宣布项目完成。这不是蠢,是基于不完整信息的合理推论。问题在于模型没有结构化的方式知道"完成"到底意味着什么。
两种失败的共同根源:AI对项目状态没有持久的、结构化的理解,而这种理解无法跨越会话边界存活。
Anthropic的解法是把任务记忆外部化。他们设计了一个两步架构:先跑一个"初始化Agent",它不写功能代码,只做一件事——创建一份200多个具体功能的清单,每个功能标记为"未完成",再加一个进度文件和环境启动脚本。之后每次会话都由"编码Agent"执行:先读功能清单看哪些没做,一次只处理一个功能,做完更新清单和进度文件,最后提交代码。
一个细节值得停下来说。功能清单为什么用JSON格式而不是Markdown? JSON是一种结构严格的数据格式,每个字段都有固定位置,像表格;Markdown更像随手写的笔记,格式自由。经验表明,模型对JSON文件比Markdown更"敬畏"。JSON的严格约束让模型不太可能随手乱改。Markdown太灵活——模型兴起时可能直接重写整个文件。你希望功能清单是模型小心翼翼更新的东西,不是它随手就能改写的东西。文件格式的选择影响模型的行为模式,这就是Harness设计的颗粒度。
功能列表是认知锚点——它让每一个新的AI会话在几秒内就知道:什么做了,什么没做,下一步该做什么。
这个模式同时消灭了两种失败:清单防止"以为做完了","一次一个功能"的约束防止"什么都想做",代码提交保证每次会话结束时的状态是干净的。
但这只是一个团队的做法。如果只有一家公司发现了这个规律,可能是巧合。让我们看看另一个极端案例。
 Martin Fowler 在 X 上关于 Harness Engineering 的推文示意图(Python 画的图)
Martin Fowler 在 X 上关于 Harness Engineering 的推文示意图(Python 画的图)2025年8月,OpenAI的Codex团队启动了一个实验:开一个代码仓库,禁止人工写代码。 每一行代码——应用逻辑、测试、CI配置(持续集成,自动化测试和部署的流程)、文档、内部工具——全部由AI Agent写。人类只负责指方向。
五个月后,仓库里有大约100万行代码、1500个合并的PR(Pull Request,代码变更请求)。三个工程师驱动了大部分工作,平均每人每天处理3.5个PR。团队从三人扩到七人后,至少在PR吞吐量这个维度上,人均产出并未下降——这跟大多数软件团队扩张时的经验完全相反。这不是demo,是每天有几百人使用的真实内部产品。
他们在2026年2月写了一篇详细报告分享教训。核心信息跟SWE-agent论文一致:瓶颈从来不在模型能力,始终在环境设计。
最值得讲的是他们在知识管理上踩的坑。早期试过一种"朴素"方案:写一份超大的AGENTS.md文件(类似说明书),把Agent需要知道的所有规则、架构约定、约束全塞进去。
失败了。 四个原因让它不可能成功:一、上下文是稀缺资源,巨型说明书挤占了任务和代码的空间;二、当所有东西都标为"重要",就没有什么是重要的——模型开始随机匹配而不是有意识地导航;三、代码库在演进,单体文档很快过时变成"陈旧规则的坟墓";四、无法验证这些规则是否真的被遵守。
解决方案是渐进式披露(Progressive Disclosure)——只给Agent一个简短的入口文件(约100行),指向仓库里更深层的文档。Agent从最小的起点出发,按需去读更详细的内容。这跟SWE-agent的搜索上限50条是同一个思路:不要预先给AI所有信息,给它定位自身的最小值和寻找更多信息的路径。
另一个反直觉的教训来自合并流程。当AI的产出速度远超人类的审查速度时,传统的代码审查规范反而成了瓶颈。 OpenAI的做法是把架构约束编码成自动化检查——自定义的Linter违反规则时自动拒绝代码变更,错误信息专门写给Agent看,包含具体的修复指令。同时大幅缩短PR的生命周期,因为在高吞吐量环境下,纠错是廉价的,等待是昂贵的。
工程师的主要工作变了:你停止调试代码,转而调试生产代码的系统。
不再问"我该怎么修这个bug",而是问"环境里缺了什么能力,导致这个bug出现"。每一次失败都是关于环境需要什么的信号——这是一种全新的工程思维方式。
回到我们这个系列的语境。在本系列《五大工程死结》(A2)中,我们提到过一个观察:在SWE-bench等主流AI编程基准测试上,同一个模型在不同工程环境下的性能差异,远大于换一个前沿模型带来的差异——SWE-agent的消融实验已经量化了这一点,而SWE-bench排行榜上的数据也持续印证这个规律。
当时只是呈现了这个观察。现在可以解释为什么了。
SWE-agent的实验给出了微观机制:搜索上限、文件查看器、语法检查、上下文折叠——每一个都在管理模型的认知负荷,让有限的推理能力用在刀刃上。Anthropic的双Agent架构给出了跨会话机制:功能列表、进度文件让模型在多次会话中保持对项目状态的连续理解。OpenAI的百万行实验给出了规模化机制:仓库即真相、渐进式披露、机械化强制——让AI驱动的开发在组织层面可持续运转。
三个团队在三个不同的尺度上解决了同一类问题。不是模型问题,全是环境问题。这不是巧合,是同一个规律在三个尺度上的投影。
如果把三个团队的方案叠在一起,一件有趣的事情出现了——五条设计原则被独立发明了三次。
渐进式披露:不要预先给Agent所有信息。 只给最小入口和寻找更多信息的指针。SWE-agent的搜索上限、OpenAI的简短入口文件、Anthropic的启动序列——都是这个原则的具体化。认知原因很清楚:上下文是有限资源,前置信息有不成比例的影响力。一个简短、聚焦的入口比一份详尽的说明书更有效。
工作树隔离:一个Agent,一个独立工作目录。 多个Agent并行工作时不互相踩踏。跟人类工程师用分支开发功能是同一个思路,只是对Agent更严格——它们没有"注意到冲突"的能力,必须靠架构保证物理隔离。
仓库即唯一真相:Agent对非正式知识是盲的。 存在Slack讨论、Google文档或某个人脑子里的信息,对Agent来说就是不存在。所有规则、架构约定、需求都必须编码进仓库的机器可读文件里。OpenAI早期的AGENTS.md失败就是反面教材——规则写在单体文档里而不是编码进仓库的结构化检查,等于不存在。如果Agent不能从仓库里读到它,它就不存在。这对团队的文档习惯有深远影响——文档不再只是给人看的,它是人类意图变得对AI可读的机制。
机械化架构强制:当每人每天3.5个PR时,人工审查扩展不了。 解法是把架构约束写成自动检查。关键原则:强制执行边界和不变性(如依赖方向、接口契约),不管具体实现。OpenAI的自定义Linter和SWE-agent的编辑时语法检查,是同一个原则在不同粒度上的实现。给Agent在明确定义的结构内以充分自主权。
集成反馈循环:缩小行动与后果之间的距离。 语法错误在编辑时抓而不是测试时,UI问题通过浏览器自动化看而不是读代码猜,运行时错误通过可观测性工具查而不是推断。反馈越快,错误级联越短——这对AI尤其关键,因为未被立即捕获的错误会在上下文里累积,拉低后续所有推理的质量。
互联网的变革不是因为HTML存在,而是因为搜索引擎和浏览器让互联网变得可导航。移动端的变革不是因为智能手机存在,而是因为应用商店让大规模开发成为可能。AI Agent正在遵循同样的模式——能力已经在那里了,问题是谁能构建出让这种能力变得可靠的环境。
说到底,这篇文章在说什么?
过去两年,三个独立团队在三个不同尺度上撞上了同一面墙,得出了同一个结论:瓶颈不在模型,在环境。 SWE-agent用数据量化了它,Anthropic在产品中验证了它,OpenAI在百万行代码的规模上确认了它。
这意味着一个判断标准的转移。评价一个AI编程工具的技术含量,不是看它接了哪个模型、跑分多少——而是看它给模型构建了什么样的信息环境:模型能看到什么?犯错后多快能发现?跨会话的状态怎么传递?
这三个问题的答案,比"底层用什么模型"重要得多。模型排行榜上的分数之争、提示词的微调技巧——这些是噪音。Harness Engineering不是一个提示词工程问题,是一个系统工程问题。而且是目前AI应用领域里,最被低估的工程问题。
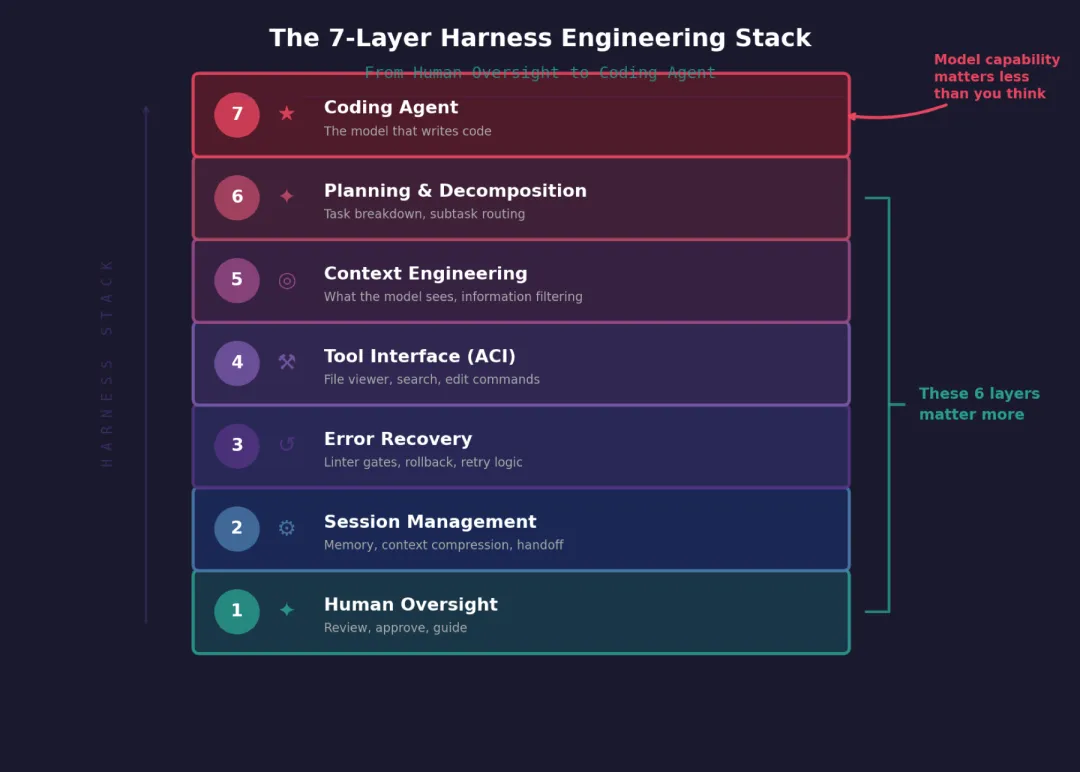 Awesome Agent Harness:七层技术栈从人类监督到编码Agent
Awesome Agent Harness:七层技术栈从人类监督到编码Agent降临派手记 · 丁仪执笔 · 2026-03-21
数据来源声明
- SWE-agent论文:普林斯顿大学NLP研究组,2024年发表(NeurIPS 2024,arXiv:2405.15793)。性能数据来自论文主实验(前最佳方法约3.8% vs SWE-agent 12.47%)及消融实验(SWE-bench Lite子集,shell-only基线约7.3% vs SWE-agent 18.00%,差距超10个百分点)
- OpenAI Harness Engineering报告:2026年2月发布,描述Codex团队五个月零人工代码实验
- Anthropic双Agent架构:来自Claude Agent SDK技术文档及Claude Code开发过程的公开分享
- Martin Fowler评论:来自其X(Twitter)账号公开发言
- SWE-bench排行榜规律(环境差异 > 模型差异):来自SWE-agent消融实验及SWE-bench公开排行榜的持续观察
独家项目拆解、AI 快讯、每日日报、学习资料分享——都在读者群。
扫码加入,一起追踪 AI 前沿。
群二维码
