四个维度,还原AI竞赛的真实图景
2026年3月,全球AI大模型的竞争格局正在经历一场静水深流的重构。
每个月,各大评测平台都会发布最新榜单,排名此消彼长,话题层出不穷。但对于关注AI产业的人来说,单一维度的排名往往只能看到冰山一角——综合能力强的模型,未必是开发者最愿意调用的;调用量高的模型,未必在品牌可见度上占优;成本低的模型,未必能在核心能力上对标国际顶尖水平。
本文基于LMArena、OpenRouter、Similarweb、SuperCLUE四大平台的最新数据,从综合能力、网络流量、API调用成本、品牌可见度四个维度,为你呈现2026年3月全球大模型竞争的全景图谱。
一、综合能力榜:国际巨头仍占鳌头,国产模型首次闯入前十
榜单数据(截至2026年3月2日,据LMArena公开报道)
根据全球公认的大模型竞技场LMArena最新榜单,综合排名如下:
| 排名 | 模型 | 所属国家/机构 | 备注 |
|---|
| 1 | claude-opus-4-6 | 美国/Anthropic | 综合能力登顶 |
| 2 | gemini-3.1-pro-pr | 美国/Google | 多模态能力强劲 |
| 3 | grok-4.20-beta1 | 美国/xAI | 实时信息处理出色 |
| 4-8 | 多家国际顶尖模型 | 美国为主 | 具体排名暂缺* |
| 9 | Seed 2.0 | 中国/字节跳动 | 首次进入前十的国产模型 |
| 10-15 | 多家国际及国产模型 | - | 具体排名暂缺* |
| 16 | GLM-5 | 中国/智谱AI | - |
| 17 | Ernie-5.0-0110 | 中国/百度文心 | - |
| 18 | Qwen3.5-397b | 中国/阿里千问 | - |
| 19 | Kimi-K2.5-thinking | 中国/月之暗面 | - |
| 20 | 数据暂缺 | - | - |
注:LMArena作为商业化运营的评测平台,其完整TOP20榜单需付费订阅获取。以上排名根据公开报道(雷峰网、财联社等)整合,部分排名暂缺。榜单具有实时波动性,本文数据截至3月2日。
细分能力亮点(来自LMArena子榜及其他专业评测)
除了综合排名,国产模型在多个细分赛道上展现出“错位竞争”的实力:
视觉理解(Vision):Seed 2.0排名全球第4
代码能力(Coding):Seed 2.0排名全球第7;GLM-5在网页开发赛道排名第8
数学推理(Math):Kimi-K2.5-thinking排名全球第8
专家知识(Expert):Kimi-K2.5-thinking排名全球第10
开放模型阵营:DeepSeek-R1(0528)稳居第一,在编程测试等细分领域表现优异
客观分析
国际顶尖模型依然占据绝对优势。 榜单前三被美国模型包揽,前八名中尚无国产模型,这反映出在通用综合能力维度上,中美之间仍存在明显差距。
但国产模型首次实现“集群化突破”。 字节跳动的Seed 2.0成为首个闯入全球前十的国产模型,这是一个里程碑式的事件。更重要的是,在TOP20中,国产模型占据了至少5个席位(第9、16-19位),形成了“多点开花”的冲击态势。
在细分能力上,国产模型展现出“错位竞争”的特点——在视觉理解、代码、数学推理等硬核能力上已经具备与国际顶尖模型正面竞争的实力,但在创意写作、指令遵循的细腻程度等“软实力”维度,仍是未来追赶的主要目标。
值得注意的是,搜索(Search)赛道依然是国产模型亟待攻克的堡垒——目前全球前十排名中尚无国产模型上榜,该领域仍由Grok、GPT和Gemini等把持。
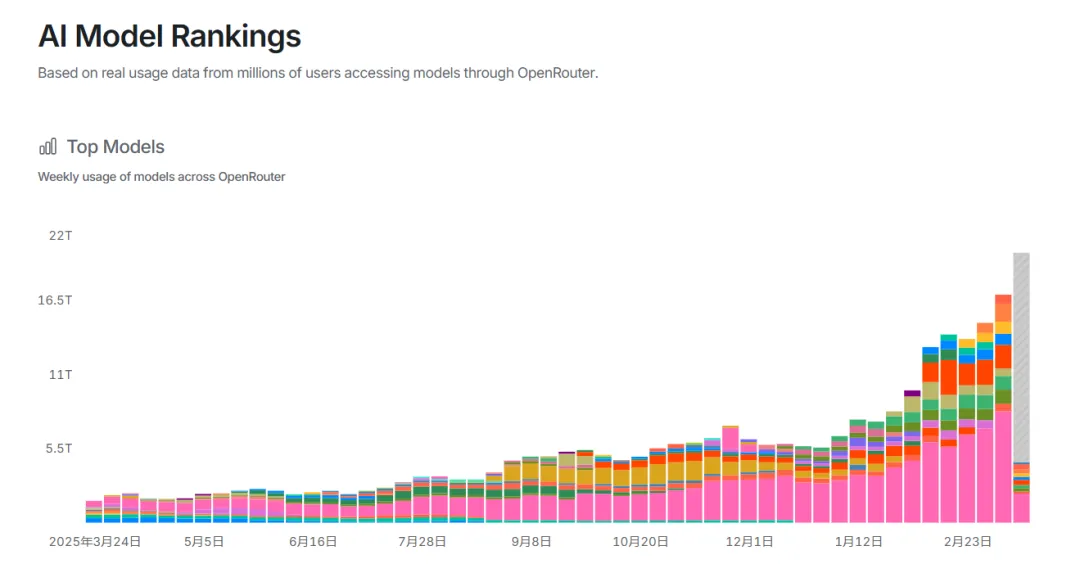
二、网络流量榜:中国模型连续两周霸榜,市场用脚投票
榜单数据(截至2026年3月15日)
根据AI模型聚合平台OpenRouter最新发布的周度调用量数据:
总量对比:
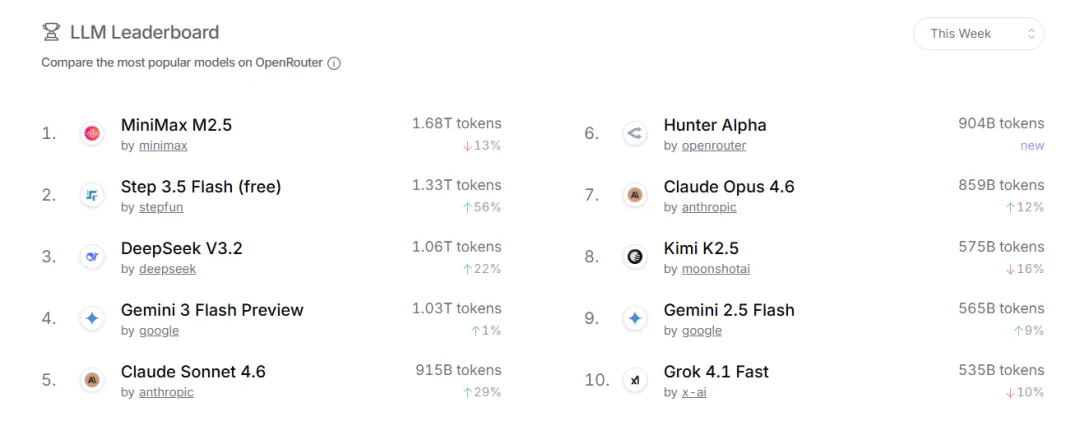
单模型调用量Top 10(中国模型表现):
| 排名 | 模型 | 周调用量(万亿Token) | 备注 |
|---|
| 1 | MiniMax M2.5 | 1.75 | 连续五周蝉联冠军 |
| 2 | 阶跃星辰Step 3.5 Flash | 1.34 | 环比增长79% |
| 3 | DeepSeek V3.2 | 1.04 | 环比增长25% |
| 7 | Hunter Alpha | 0.666 | 3月11日上线,4天冲进前十 |
关键背景:OpenRouter用户中,美国开发者占比47.17%,中国开发者仅占6.01%。这意味着中国模型是在“客场”环境中,纯粹凭产品力赢得全球开发者的选择。
客观分析
调用量是“市场选票”的真实体现。 当中国模型连续两周在调用量上超越美国,并且包揽全球前三时,这已经不能用“偶然”来解释。
弗若斯特沙利文中国业务主管合伙人陆景指出:“当前数万亿Token级别的调用量,已不再主要由测试性场景构成,而是由一批高频、规模化、可持续付费的商业应用所支撑。”这意味着,中国模型已经完成了从“技术可用”到“规模商用”的跨越。
MiniMax M2.5的持续领跑尤其值得关注。其采用混合MoE架构,推理阶段Model FLOP利用率超75%,远高于行业40%-50%的平均水平。这种技术上的极致优化,直接转化为了市场上的绝对优势。
神秘模型Hunter Alpha的异军突起则揭示了另一个趋势:专为智能体(Agent)设计的模型正在成为新风口。该模型上线仅4天便冲进全球第七,精准卡位了OpenClaw等Agent框架爆发带来的增量需求。
三、API调用成本榜:极致性价比,价差高达22倍
榜单数据(截至2026年3月)
根据公开API定价数据对比:
| 模型 | 输入价格(美元/百万Token) | 输出价格(美元/百万Token) | 性价比定位 |
|---|
| MiniMax M2.5 | 0.3 | 1.1 | 极致性价比 |
| DeepSeek V3.2 | 约0.5 | 约2.0 | 高性价比 |
| 阶跃星辰Step 3.5 | 约0.4 | 约1.5 | 高性价比 |
| Claude Opus 4.6 | 5.0 | 25.0 | 高端定位 |
| GPT-5系列 | 3.0-15.0 | 15.0-75.0 | 分层定价 |
| Gemini系列 | 1.0-5.0 | 2.0-15.0 | 中等偏高 |
价差对比:
客观分析
成本优势是中国模型赢得市场的核心武器。 当技术能力差距缩小到3-6个月,而价格差距扩大到10倍以上时,全球开发者的“用脚投票”就成了一种理性选择。
这种极致性价比并非简单的“价格战”,而是源于技术架构的根本性优化。以MiniMax为例,其混合MoE架构实现了2300亿参数量与仅100亿激活参数量的平衡,既保障顶级性能,又大幅降低推理成本。
对于中小企业而言,这意味着AI应用的门槛被大幅拉低。 运行复杂智能体的成本可低至每小时1美元,仅为美国同类模型的1/4到1/5。当算力成本不再成为障碍,更多的创新场景才有可能被探索和落地。
但硬币的另一面是:低价策略能否持续? 有分析指出,部分国产模型厂商面临“营收增长但亏损扩大”的困境。性能、开源与商业化之间的平衡,仍是未来发展的核心命题。
四、品牌可见度榜:AI正在重塑品牌发现的新规则
榜单数据(截至2026年1月)
Similarweb最新发布的《2026年生成式AI品牌可见度报告》揭示了一个全新的维度:在AI回答中被提及的份额。
关键趋势:
| 指标 | 数据 | 含义 |
|---|
| 美国消费者在发现阶段使用AI的比例 | 35% | 远超使用搜索的13.6% |
| 从AI引荐的流量占比 | <1% | 用户很少点击链接 |
| ChatGPT用户停留时长 | 15分钟 | 远超Google引荐的8分钟 |
| 转化率对比 | 7% vs 5% | AI引荐>Google引荐 |
分行业品牌可见度冠军:
| 行业 | 品牌 | 可见度表现 |
|---|
| 金融 | Chase | 15.89%提及份额 |
| 旅游 | Expedia | 18.18%提及份额 |
| 电子产品 | Apple | 54.38%提及份额 |
| 美妆 | CeraVe | 27.17%提及份额 |
| 时尚 | Nike | 指数100(基准) |
| 新闻 | Reuters | 指数100(基准) |
最值得关注的“超常发挥”品牌(AI排名远超搜索排名):
| 品牌 | 行业 | AI排名 | 搜索排名 | 差值 |
|---|
| WhoWhatWear | 时尚 | 27 | 96 | +69 |
| Bankrate | 金融 | 13 | 81 | +68 |
| NerdWallet | 金融 | 7 | 73 | +66 |
| ScienceDirect | 新闻 | 18 | 81 | +63 |
客观分析
Similarweb的这份报告揭示了AI时代品牌建设的根本性变革:可见度比流量更重要。 报告明确指出:“AI平台被设计用来回答,而不是用来路由。”这意味着,当用户向ChatGPT询问“哪款面霜适合敏感肌”时,得到答案的那一刻,购买决策就已经形成——无论用户是否点击链接。
品牌规模不再是AI可见度的可靠预测指标。 在美妆行业,CeraVe凭借“皮肤科医生推荐”的深度内容,在AI提及份额上超越了拥有10倍搜索量的Ulta。在新闻行业,路透社的AI排名远高于其搜索排名,而《纽约时报》和《华尔街日报》因屏蔽AI爬虫,反而排在《卫报》之后。
对于中国企业而言,这既是挑战也是机遇。 目前该报告主要基于美国市场数据,尚未系统评估中国品牌在全球AI回答中的可见度。但随着DeepSeek、MiniMax等中国模型在全球开发者中的普及,中国品牌如何在这些模型的回答中被提及,将成为出海战略的新课题。
Similarweb的洞察指出:“AI没有创造趋势,但它正在放大趋势。”那些能够为特定问题提供完整、结构化答案的品牌,无论规模大小,都将获得超越其传统市场地位的AI可见度。
五、四个维度的综合研判:趋势与隐忧
趋势一:竞争维度正在分化
过去,人们习惯于用“综合能力”一维定胜负。但现在,四个维度呈现出明显的分化:
综合能力:国际顶尖模型(Claude、Gemini)仍占据绝对优势,中国模型首次进入前十但差距仍在
市场调用:中国模型凭借极致性价比实现“客场逆转”,连续两周霸榜
成本定价:中国模型的性价比优势高达10-20倍,成为中小企业首选
品牌可见度:一个全新的竞争维度正在形成,内容深度比品牌规模更重要
趋势二:智能体(Agent)成为新增长极
Hunter Alpha上线4天冲进全球第七,OpenClaw引爆的“养龙虾”热潮推高调用量,这些信号共同指向一个方向:AI竞争正在从“单轮对话”向“多步骤任务执行”演进。
专为智能体设计的模型,需要具备长期规划、复杂推理、高精度执行的能力,其Token消耗量是普通对话的数百倍。这既是新的技术赛道,也是新的商业蓝海。
趋势三:商业闭环正在形成,但隐忧犹存
调用量的爆发拉动了整个算力产业链,摩根大通预测中国AI推理Token消耗量五年增长370倍。同时,MiniMax等厂商的API收入持续攀升,形成了“技术迭代→成本下降→调用激增→收入反哺”的正向循环。
但隐忧同样存在:
盈利困境:MiniMax上市后首份财报显示,2025年营收增长159%,但亏损同比扩大302%至18.7亿美元。高增长与高亏损并存,烧钱模式能否持续?
开源与商业化的矛盾:阿里巴巴Qwen技术负责人离职事件,暴露出公司在营收压力与开源策略之间的艰难平衡。
软实力差距:LMArena榜单显示,国产模型在创意写作、指令遵循的细腻度上,与顶尖模型仍有差距。
安全风险:随着OpenClaw等Agent框架普及,安全漏洞和Token“吞金”问题日益突出,工信部已就此发布预警。
结语:多维竞争时代,如何读懂AI棋局
回看这四个维度的最新数据,一个清晰的图景浮现出来:
在综合能力上,中国模型正在缩小差距,但尚未实现全面超越。 Seed 2.0首次闯入全球前十是里程碑,DeepSeek-R1稳居第6、国产模型占据TOP20至少5席的事实提醒我们:技术攻坚正在加速,但前八名仍由国际模型主导的局面说明差距犹存。
在市场调用上,中国模型已经实现实质性领先。 连续两周霸榜、包揽前三、在“客场”赢得全球开发者选择——这些不是偶然,是极致性价比和技术优化的必然结果。
在成本定价上,中国模型构建了10倍以上的护城河。 这对中小企业意味着什么?意味着过去只有大厂才用得起的AI能力,现在每个小企业都能负担。
在品牌可见度上,一个全新的游戏规则正在形成。 无论你来自哪个国家、规模多大,只要能为用户问题提供最优质的答案,就能在AI时代赢得品牌曝光。
对于关注AI产业的人来说,单一维度的排名已经不足以支撑判断。只有把四个维度拼在一起,才能看清这盘棋的全貌:
2026年,全球AI竞赛进入了下半场。下半场的规则不再是“谁更聪明”,而是“谁更好用、更便宜、更可持续”。在这场多维竞争中,最终的赢家,未必是单项冠军,而是那个能在所有维度上找到最佳平衡点的选手。
(数据来源:LMArena、OpenRouter、Similarweb、SuperCLUE,截至2026年3月16日。注:LMArena完整TOP20榜单需付费订阅获取,本文根据公开报道整合,部分排名暂缺。)