最新OpenClaw模型排行榜:第一名不是最贵的,而是性价比更高的它
- 更新时间 2026-03-16 11:02:21

题图摄于故宫
基于PinchBench真实测试数据,告诉你哪款大模型最适合Agent工作流
后台有好几个读者问:用 OpenClaw 搭建的智能体系统,到底该选哪个大模型?
这确实是个让人头疼的选择题。市面上模型那么多,参数不同,价格各异,真用起来,谁更靠谱?
本来想先写一篇关于 OpenClaw 部署模式的文章,但既然模型的选择被问到了,就先说说吧。
最新数据刚出炉(3月14日更新),我们一起来看看,到底哪些模型是真正能打的。
选错模型的代价,比想象的大
给你算笔账:
核心系统提示词:3000-5000 token 上下文文件注入:3000-14000 token 工具 schema 定义:约 8000 token
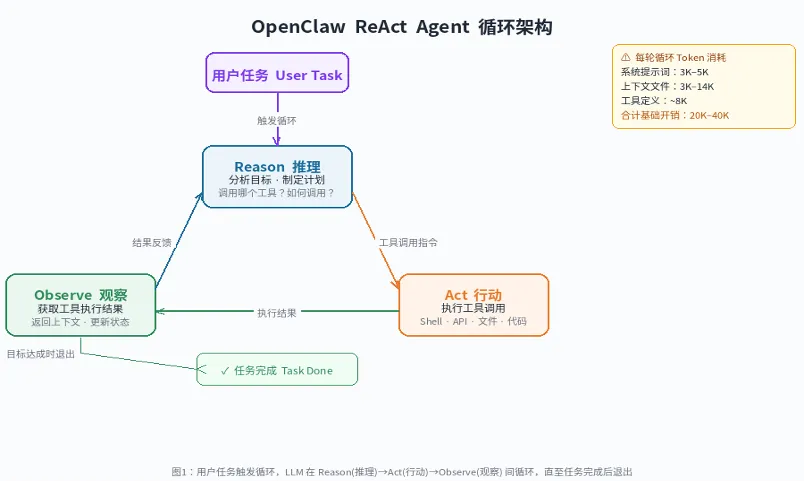
十强榜单:头部选手差距不到4个百分点
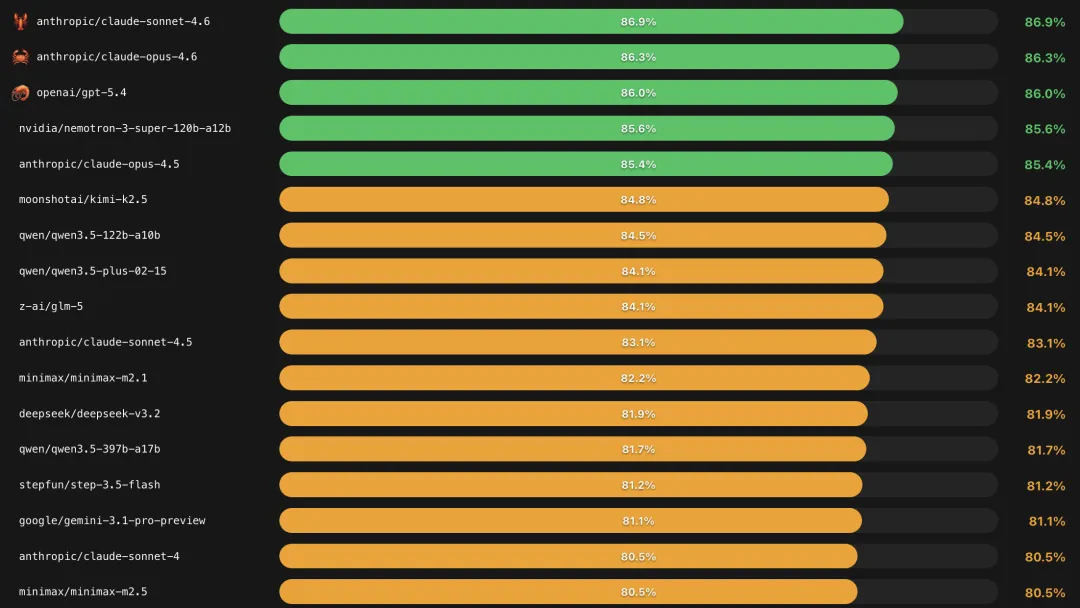
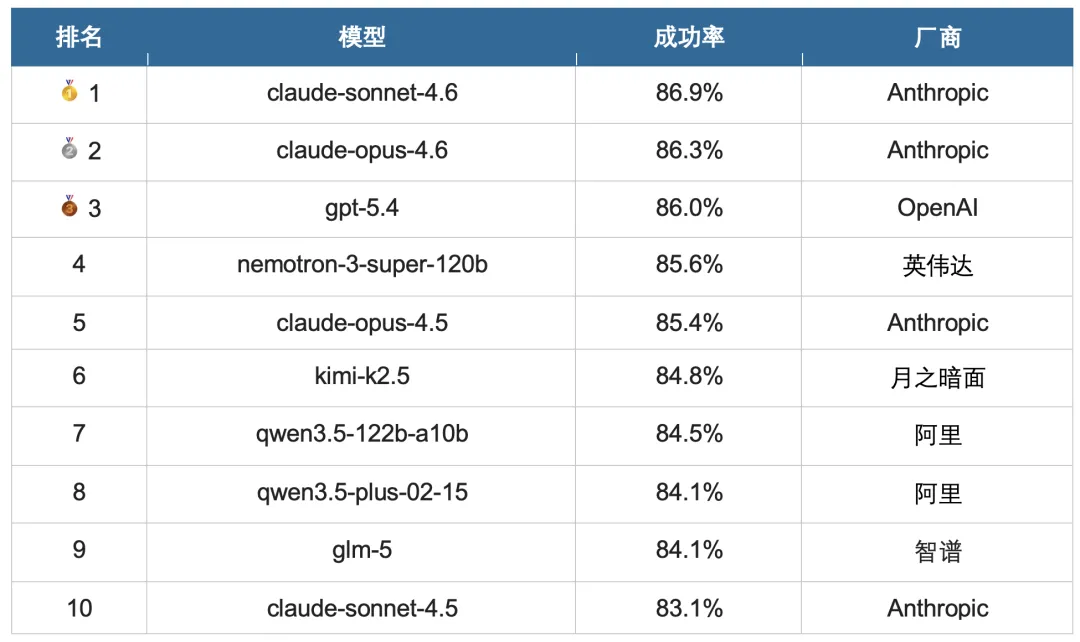
看完这张表,有几的个发现挺有意思的:
① Claude 霸榜前二,但优势并不悬殊。
Sonnet 4.6(86.9%)和 Opus 4.6 (86.3%)分居一二,GPT-5.4(86.0%)紧随其后。三者差距不足1个百分点,基本可以算作并列第一梯队。
② 英伟达杀入前四,这匹黑马有点意外。
英伟达的 Nemotron-3-super-120b 模型(3月11日发布)以85.6% 排名第四,比 Claude Opus 4.5还高。关键它是开源模型,可以本地部署,对预算有限的用户很有吸引力。
③ 中国模型集体发力,性价比优势明显。
Kimi-K2.5(84.8%)、Qwen3.5-122B(84.5%)、Qwen3.5-Plus(84.1%)、GLM-5(84.1%)四个模型进入前十,API 价格远低于欧美旗舰模型。
在前十名之外,同样值得关注的是:MiniMax M2.1 以 82.2% 排名第 11,MiniMax M2.5 排名第 17。因为M2.5 是今年 2 月才正式发布的新模型,输出价格仅 $0.95/M,约为 Claude Sonnet 的 1/16,在 Agent 任务上还支持 196K 上下文与全自动缓存,是高性价比选项中的一匹黑马。
阶跃星辰(StepFun)的 Step-3.5-Flash 以 81.2% 排名第 14,同样值得关注:输出价格低至 $0.30/M,推理速度峰值可达 350 tokens/秒,其官方 GitHub 也专门提供了 OpenClaw 集成教程。
④ 更贵不等于更好。
Sonnet 4.6 的成功率高于 Opus 4.6,而 Sonnet 的价格只有 Opus 的五分之一。这是在 OpenClaw 场景中最具颠覆性的发现:旗舰模型不一定有更好的实际表现。
性价比排名:同样的钱能完成多少任务
成功率告诉你模型能不能完成任务,而性价比告诉你用同样的钱能完成多少任务。对 OpenClaw 这类 Agent 密集型工作,后者往往更重要。
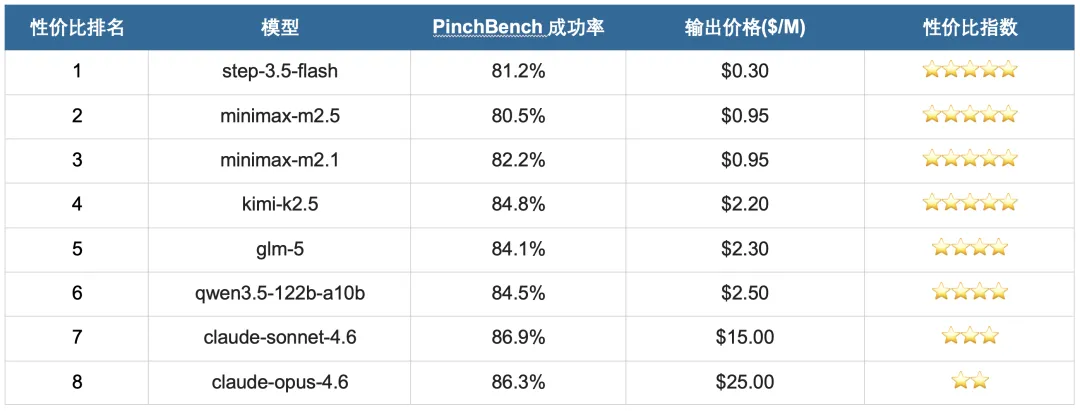
(Nemotron-3-super-120b 价格数据暂缺)
从表中能看出几个规律:
Step-3.5-Flash 以 0.30 美元/百万 token 的极低价格和 81.2% 的成功率,位居付费模型性价比榜首。紧随其后的 MiniMax M2.5 和 M2.1 同样具备极高性价比。
Kimi K2.5在成功率(84.8%)和价格(2.20美元/百万token)之间取得了最佳平衡,是国内用户综合性价比最高的选项之一。
Claude Sonnet 4.6 虽然价格较高,但以旗舰级成功率(86.9%)仍然保持竞争力。
选模型的四个核心考量
光看排名还不够,你得根据自己的实际需求来选。
PinchBench 的数据揭示了一个重要规律:在文件操作、数学计算、基础编程这些确定性任务上,前十名模型几乎都是满分。差异体现在创意写作和复杂综合推理上。
Claude Sonnet 4.6 和 Opus 4.6 刚宣布(2026年3月13日)100万 token 上下文窗口正式上线,标准价格,不再收长上下文溢价。GPT-5.4 支持 105万 token,超过 27.2万 后双倍计费。NVIDIA Nemotron 3 Super 原生支持100万 token 上下文。
这是智能体场景最容易被忽视的维度。模型需要严格按照 JSON 格式输出工具调用,一旦格式错了,整个智能体循环就断了。
前十名模型在这一维度上都过了关,但低于 78% 成功率的模型(比如gpt-oss系列)往往在工具调用链上不太稳定,不建议用于生产环境。
Agent 循环意味着模型要多次串行调用。如果每次调用延迟 3-5秒,一个 10 步的任务就需要 30-50 秒。
NVIDIA Nemotron 3 Super 的推理速度达到 430 tokens/秒,是前十名中最快的之一,对实时性要求高的场景有优势。Kimi K2.5 的首 token 延迟约 2.75 秒,略高于平均水平。Claude 系列的 API 延迟比较稳定。
四类场景的最佳匹配
PinchBench 排名第一(86.9%),价格是 Opus 的五分之一(3/15美元每百万 token,下同),100万 token 上下文刚刚上线,在 Agent 场景中实现了性能与成本的最佳平衡。适合大多数中重度 OpenClaw 用户。
成功率 84.8%(排名第六),但价格只有 0.45/2.20 美元,约是 Claude Sonnet 的七分之一。具备原生多智能体协调能力(最多 100 个子 Agent ),是预算敏感用户的首选。
开放权重模型,可免费在 OpenRouter 使用,也可本地部署。成功率 85.6%,推理速度 430 tokens/秒,100 万原生上下文,专为 Agent 多步骤工作负载优化,是追求完全数据控制的团队的最佳选择。
当任务涉及深度推理、复杂多步骤分析或需要最高精度时,Opus 4.6 仍是首选。虽然在整体排名上略低于 Sonnet 4.6,但在推理密集型子任务上仍有明显优势。对成本不敏感的用户可以考虑。
结语
排名第一的 Claude Sonnet 4.6 以五分之一的 Opus 价格实现了更高成功率;而 Kimi K2.5、GLM-5 等中国模型以极低价格进入前十,彻底改变了旗舰模型等于最佳选择的固有认知。
最明智的策略是:用 PinchBench 成功率划定候选模型范围,再用 API 定价和实际使用强度做最终决策。
对于大多数用户,Claude Sonnet 4.6 是最稳的起点;对于预算有限的用户,Kimi K2.5 是被低估的明星。
欢迎关注 亨利笔记, 👍 点赞 | ⭐ 收藏 | ↗️ 转发。欢迎评论区聊聊你的看法。
近期文章:
龙虾政策直击:OpenClaw 爆火背后,OPC “超级个体”时代真的来了
别再只会写提示词了!MCP+Skills这两大杀器,正在终结“AI智障”时代!
本公众号聚焦人工智能,云原生和区块链等技术原理,请立即关注亨利笔记( henglibiji ),以免错过更新。
