OpenClaw大模型排行榜来了!国产AI霸榜前10,又快又好省钱
- 更新时间 2026-03-12 22:35:37

我会用100篇干货教程,一步步带你OpenClaw从入门精通到放弃。
这是第九篇。
同一只龙虾,换个大脑,从废物变天才。模型选错,龙虾再强也白搭。
上一篇我们聊了三大零门槛安装方案。
装完之后,你可能正信心满满地打开龙虾,准备让它帮你干活。
然后发现——它连文件都找不到。
别急着怀疑人生。问题大概率不在龙虾身上,而在你给它选的大脑。
这篇,把模型选择这件事讲透。
读完你会精准知道:该选哪个模型、花多少钱、怎么搭配最划算。
01
安装只是起点,选对大脑才是关键

第二篇讲原理的时候说过——龙虾自己不聪明,聪明的是它的大脑。
OpenClaw就是一个"指挥官"——它负责接收你的指令、调用工具、组织流程。但真正理解你说了什么、决定怎么做的,是你给它接的大语言模型。
打个比方。
龙虾是一辆跑车底盘。你给它装V8发动机,它能跑出赛道成绩。
给它装个三轮车电机,它连坡都上不去。
模型选错 = 请了个不靠谱的员工。你把活分配得再好,它也完成不了。
这不是我随便说的。我们社群做过一个严格实测——同一个任务交给6个不同模型,跑了3轮。结果:GPT-5-mini全流程顺畅完成,千问Qwen3-Max在第一步就卡住了。
同一只龙虾,天壤之别。
那问题来了:市面上几十个模型,到底怎么选?
别慌。我替你做好了功课。
02
PinchBench:龙虾之父推荐的选模标准

OpenClaw创始人Peter亲自推荐了一个榜单——PinchBench。
 这个榜单专为龙虾而生,一口气测了32款主流大模型,从三个维度给你答案:
这个榜单专为龙虾而生,一口气测了32款主流大模型,从三个维度给你答案:
◦ 成功率——任务完成百分比,这是硬指标
◦ 速度——完成任务要多久,谁都不想对着屏幕干等
◦ 费用——跑一次任务花多少钱,钱包要紧
和传统的AI排行榜不一样,PinchBench不看模型会不会答题,而是看它能不能完成一整件事——查资料、写报告、调API、发邮件,全流程跑通才算过关。
重点
PinchBench由Kilo AI团队开发(GitLab前联合创始人投资),包含23个真实任务测试,采用自动化检查+LLM评审的组合评分,完全开源。
来看最新排名。
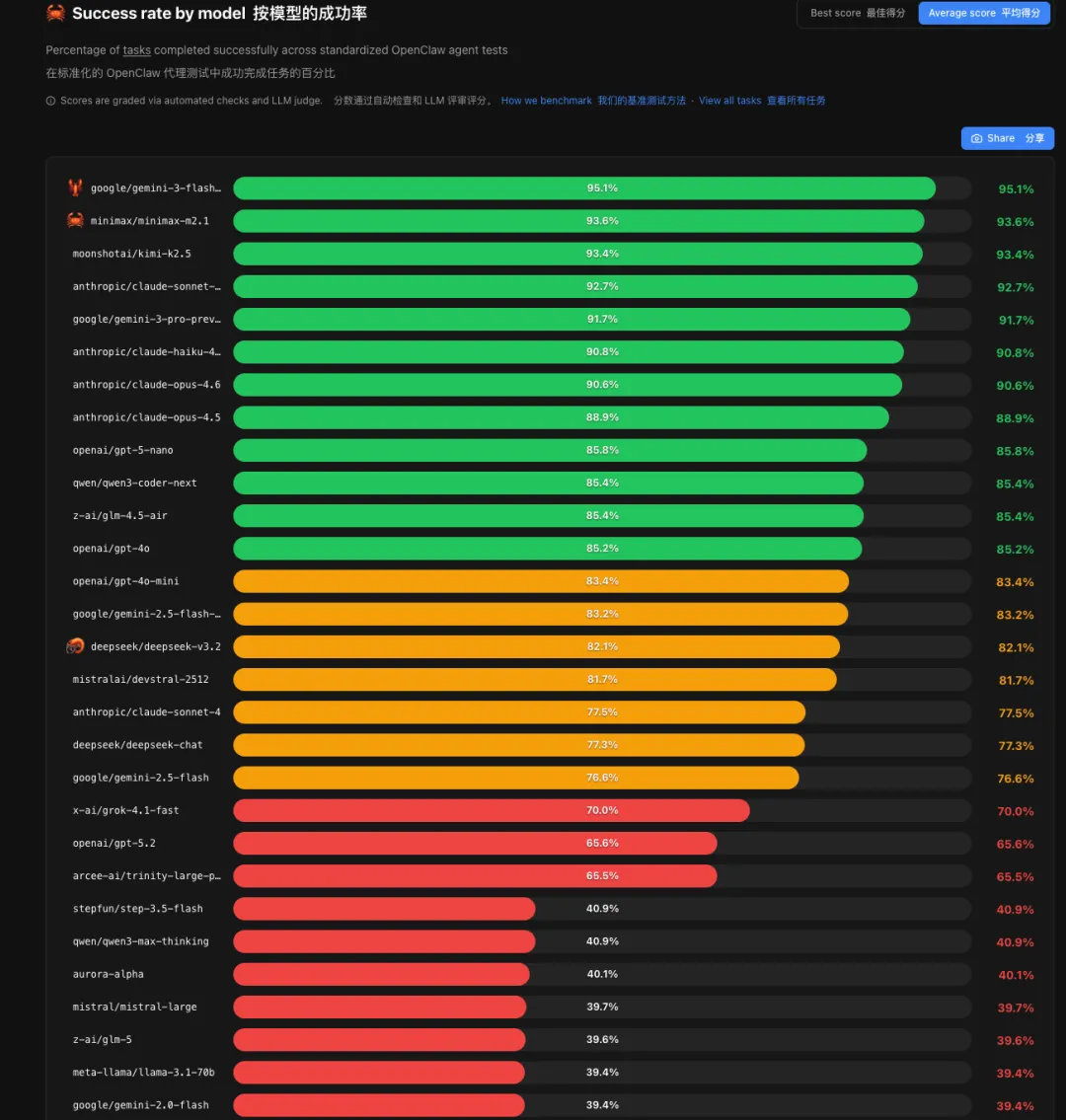
❶成功率:国产模型杀进前三
| 排名 | 模型 | 成功率 | 产地 |
|---|---|---|---|
| 1 | 95.1% | ||
| 2 | 93.6% | ||
| 3 | 93.4% | ||
| 4 | |||
| 5 | |||
| 6 | |||
| 7 |
数据来源:PinchBench,截至2026年3月
更有意思的是,Claude Opus 4.6作为Anthropic的旗舰模型,成功率只有90.6%,排第七。比MiniMax M2.1低了3个百分点。
"大"不一定"强"。至少在龙虾这个场景下,中端模型反而更香。
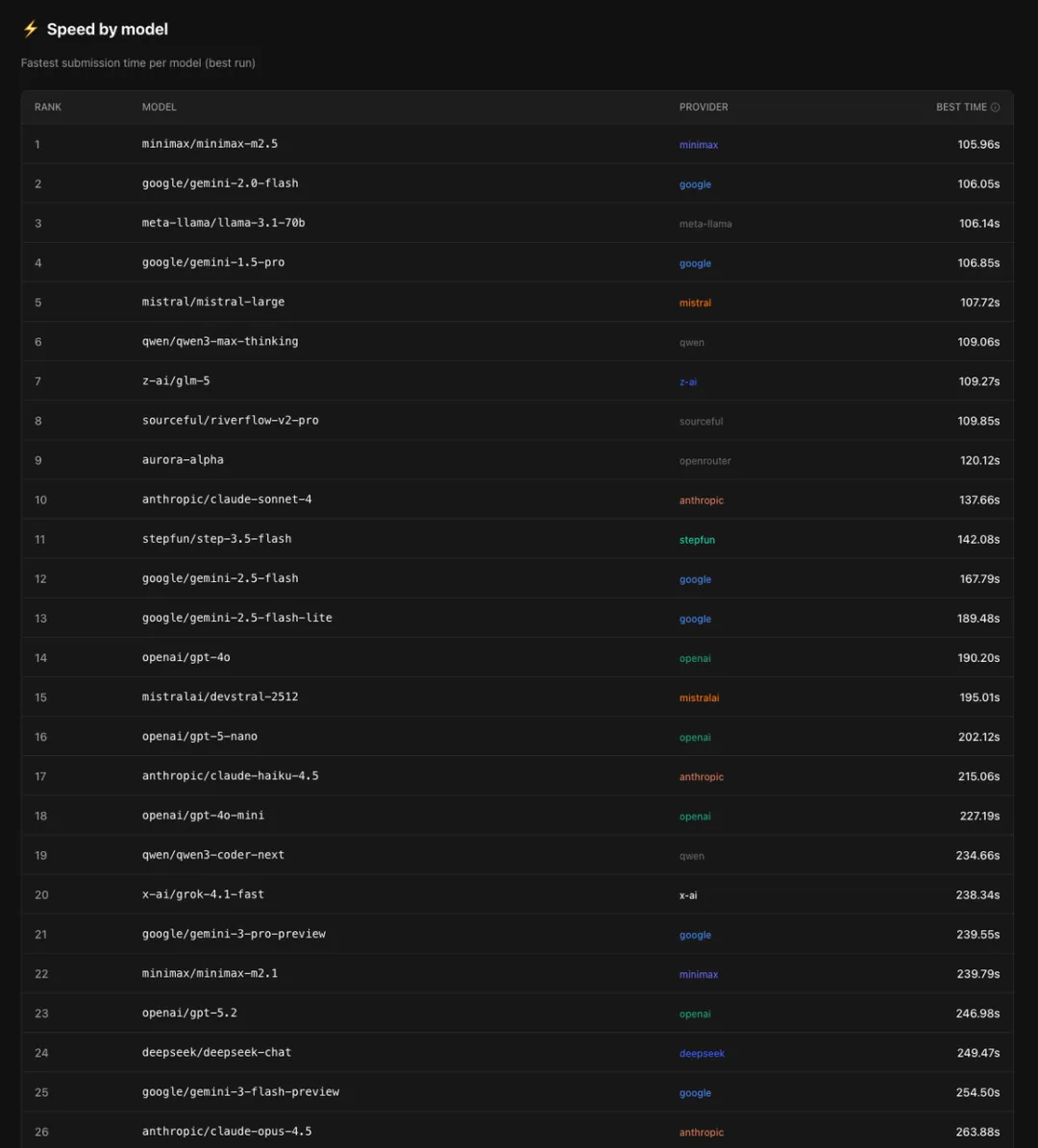
❷速度:MiniMax赢麻了
MiniMax M2.5以105.96秒完成全部测试任务,拿下速度冠军。Gemini 3 Pro用了239.55秒,是M2.5的两倍多。

规律很明显:轻量级模型普遍更快。如果你经常迭代、频繁调试,选轻量模型省下的不是时间,是耐心。
❸费用:相差200倍
GPT-5 Nano完成一次测试花0.03美元。Claude Opus 4.6花了5.89美元。
差了将近200倍。但Opus的成功率还比MiniMax低。
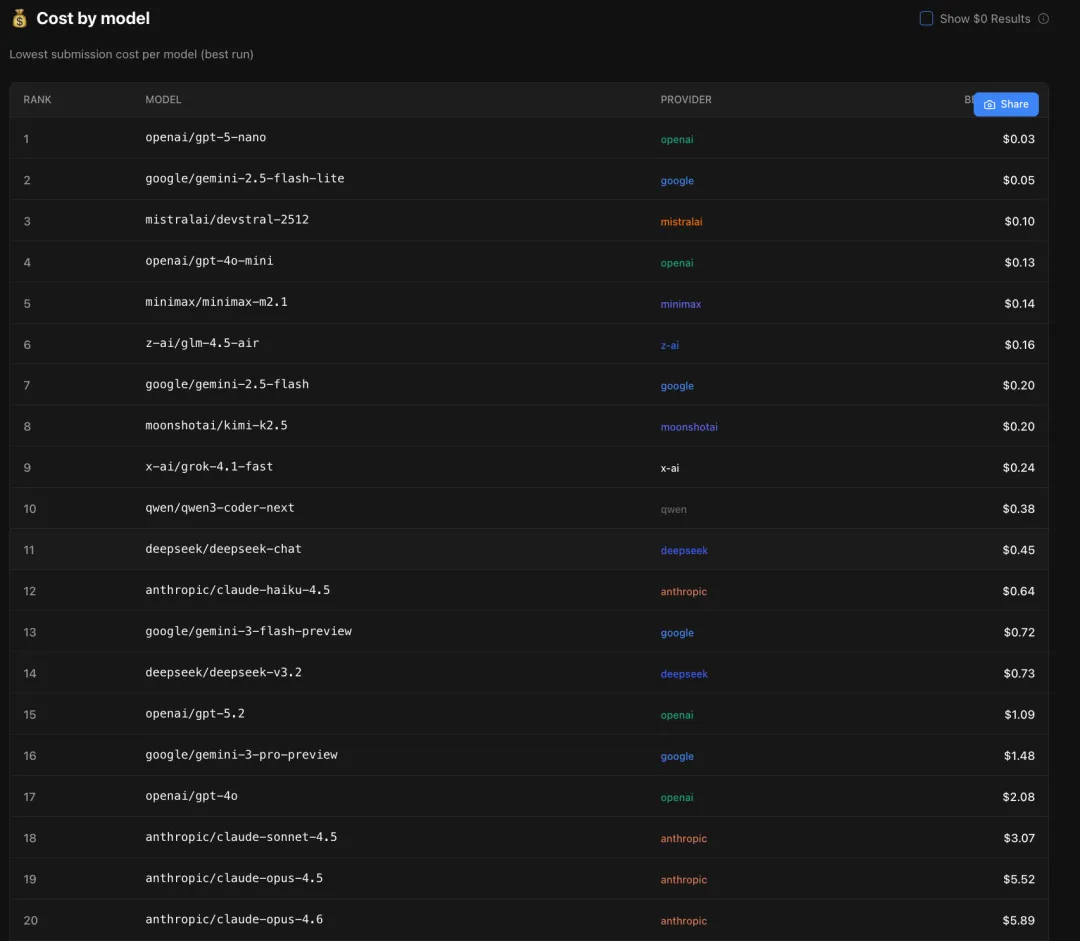
除非你对Claude有特殊的品牌信仰,否则从纯性价比角度,中端模型是更理性的选择。
03
每经实测:6个模型,3轮PK,谁活到了最后

排行榜是一回事,实际干活又是另一回事。
为了的测试更接近真实场景。我让龙虾做一件完整的事——
测试任务全流程
找文件 → 总结内容 → 搜网络资料 → 写新闻稿 → 发邮件
这条链路涵盖了文件操作、浏览器控制、信息整合、内容生成和应用操控——几乎覆盖了龙虾日常干活的所有能力维度。
6个模型,3轮测试,直接看成绩单。
| 模型 | 找文件 | 搜资料 | 写稿 | 发邮件 | 评级 |
|---|---|---|---|---|---|
| GPT-5-mini | 稳定 | ||||
| MiniMax M2.5 | 稳定 | ||||
| 智谱GLM-4.7 | 稳定 | ||||
| MiniMax M2.1 | 部分 | ||||
| Kimi K2.5 | 部分 | ||||
| 千问Qwen3-Max | 不推荐 |
逐个说几句。
千问Qwen3-Max:行动力严重不足
第一轮测试,明确告诉它文件在哪,Qwen3-Max搜了5分钟,愣是没找到。发邮件环节更离谱——不断重复指令,但没有任何实际动作。
不推荐用于复杂任务。
Kimi K2.5:能力在线,浏览器操控拉胯
文件检索没问题,5分钟内搞定。但网络搜索时频繁触发429错误(请求太快被限流),发邮件环节连续三轮都失败——控制浏览器这事,它暂时还不太行。
适合文件处理和写作,不适合需要操控浏览器的任务。
GPT-5-mini:全流程最稳
从文件检索到邮件发送,三轮测试几乎无需人工干预。偶尔出现网络连接不稳定,但自己就恢复了。
如果预算允许且能访问OpenAI API,这是目前的最优选。
一位使用OpenClaw辅助运营网店的程序员说得很直接:自己平时都是接入OpenAI的模型,效果比国产大模型好很多。
但这不意味着国产模型不能用。MiniMax M2.5和智谱GLM-4.7三轮全部通过,而且价格只有GPT-5-mini的几分之一。
没有最好的模型,只有最适合你场景的模型。
04
养虾的真正成本:从免费到月薪交给AI

先说一个很多人不知道的事实:龙虾是Token燃烧器。
普通和ChatGPT聊天,一问一答,Token消耗很低。但龙虾不一样——它每思考一步,都要把之前的所有上下文重新读一遍。
第1分钟:读文件,烧了10万Token。
第2分钟:分析网页,又把刚才的信息复习一遍,20万Token。
第3分钟:写报告,之前所有内容再来一次……
有人6小时消耗9000万Token,账单170美元。有人一天"喂虾"花400块。更有人首月消耗了1.8亿Token,账单超过2万元。
注意
安装OpenClaw不花钱,但"养龙虾"消耗的Token,比你和AI聊天要多得多。同样消耗1亿Token,用GPT-5.2 Pro要花超过1万美元,用DeepSeek V3.2只要不到70美元——差距超过150倍。
所以,模型的选择不只是"能不能用"的问题,更是"用得起用不起"的问题。
好消息是——国产模型给了你大量的免费额度。
| 模型 | 厂商 | 免费额度 | 适合场景 |
|---|---|---|---|
| Qwen-Max | 100万 | ||
| DeepSeek | 1000万 | ||
| GLM-4 | |||
| Kimi | |||
| GLM-4-Flash | 完全免费 | ||
| GPT-5-mini |
数据来源:各厂商官网,截至2026年3月
另外还有一个冷知识:字节火山引擎每天送200万tokens,百度ERNIE-Speed完全免费不限量。
有人统计过,把全球27家AI厂商的免费额度全薅一遍,保守估计能让龙虾跑2年以上,一分钱不花。
先别急着花钱。免费的路,比你想象的宽。
05
四套方案,对号入座

根据预算和需求,我给你整理了四套方案。不废话,直接看。
❶零成本方案:通义千问Qwen-Max
◦ 月成本——0元(100万tokens免费额度内)
◦ 适合——预算为零、先体验再说的用户
◦ 局限——每经实测表现垫底,复杂任务可能翻车
说白了,这个方案是用来入门的,不是用来干活的。让你先感受一下龙虾是什么东西、能做什么,等搞清楚了再升级。
❷性价比方案:DeepSeek + Qwen混用
◦ 月成本——0-30元
◦ 用法——日常简单任务用Qwen(免费),推理/编程任务切DeepSeek(便宜)
◦ 适合——愿意花点小钱但不想大出血的用户
DeepSeek V3.2的输出成本只有0.42美元/百万tokens,是GPT-5价格的二十分之一。OpenClaw支持配置Fallback机制——主力模型额度用完了,自动切换到备用模型,你甚至感知不到。
小贴士
在openclaw.json里配置多个provider,设好fallback顺序,龙虾会在主力模型被限流或额度耗尽时自动切换。类似于手机双卡双待——一张卡没信号了,自动走另一张。
❸稳定方案:MiniMax M2.5 或 智谱GLM-4.7
◦ 月成本——50-200元
◦ 验证——每经实测三轮全过,PinchBench排名前列
◦ 适合——想让龙虾真正干活、对稳定性有要求的用户
MiniMax M2.5在PinchBench速度排名第一,成功率排名第二。而且它的输入价格只有0.3美元/百万tokens,输出1.1美元/百万tokens——Claude Opus的输出价格是它的22倍。
非凡产研研究负责人宦家臣说得好:国际头部模型上限更高,但如果都是普通任务,国内的智谱GLM-4.7、Kimi K2.5都很不错。毕竟Claude太贵了,钱包受不了。
❹最强方案:GPT-5-mini
◦ 月成本——100-500元
◦ 验证——每经实测全流程无需人工干预
◦ 前提——需要能访问OpenAI API
如果你追求最高完成率、最少人工干预,且网络条件允许,这是当前的天花板。
但请注意两件事:一是费用确实不低,有人一天就烧掉几十甚至上百元;二是网络问题可能会影响体验。
四套方案速查
| 0元 | |||
| 0-30元 | |||
| 50-200元 | |||
| 100-500元 |
06
你不需要一步到位
ExcelMaster.ai创始人张和在接受采访时说了一句话,我觉得说到了点子上——
"等大模型能力再跃升一点,OpenClaw就会越来越好。哪怕它什么都不做,
就等着更新的大模型出来……OpenClaw的门槛就会降低。"
这句话揭示了一个很重要的事实。
龙虾的能力上限,取决于底层大模型。模型在快速进步。今天Qwen3-Max在每经测试里表现垫底——但三个月后,它可能脱胎换骨。
所以,选模型不需要"一步到位选最贵的"。
先用免费模型入门,感受龙虾是什么。
等你搞清楚自己的核心场景了,再切到匹配的模型。
等模型继续进步了,你的龙虾会自动变强——你什么都不用做。
龙虾的进步与普及,本质上是在等待底层大模型技术的突破。
而这件事,正在加速发生。
MiniMax的M2.5发布后,Token消耗量暴增了6倍,ARR飙升50%。Kimi完成了超过7亿美元的融资,估值跳到120亿美元。全球OpenClaw Token消耗量前五名里,中国模型占了4个。
这说明什么?
国产模型正在被大量龙虾用户验证。你的选择空间,只会越来越大。
耐心点。这才刚开始。
下一篇,我们聊一个实用问题:
《体面告别:OpenClaw 完整卸载与数据清理指南》
龙虾不是人人都养得起的。想走,得走干净。
CLI卸载、手动清理、各平台操作——一篇搞定。
关注我,别掉队。
OpenClaw vs ChatGPT vs Manus:三者谁强?
如果你正在被这三个问题困扰——
◦ 不知道该选哪个模型当龙虾的大脑
◦ Token账单超出预期不知道怎么省
◦ 想看看别人用什么模型搭配效果最好
欢迎加入「虾搞俱乐部」,一起搞明白。

扫码加入「openclaw玩家群」
想找我聊聊?加我个人微信:

言大侠个人微信
